Hello,
I would like to know why are there so many differences in performance of BCJ?
This is all in one BCJ.
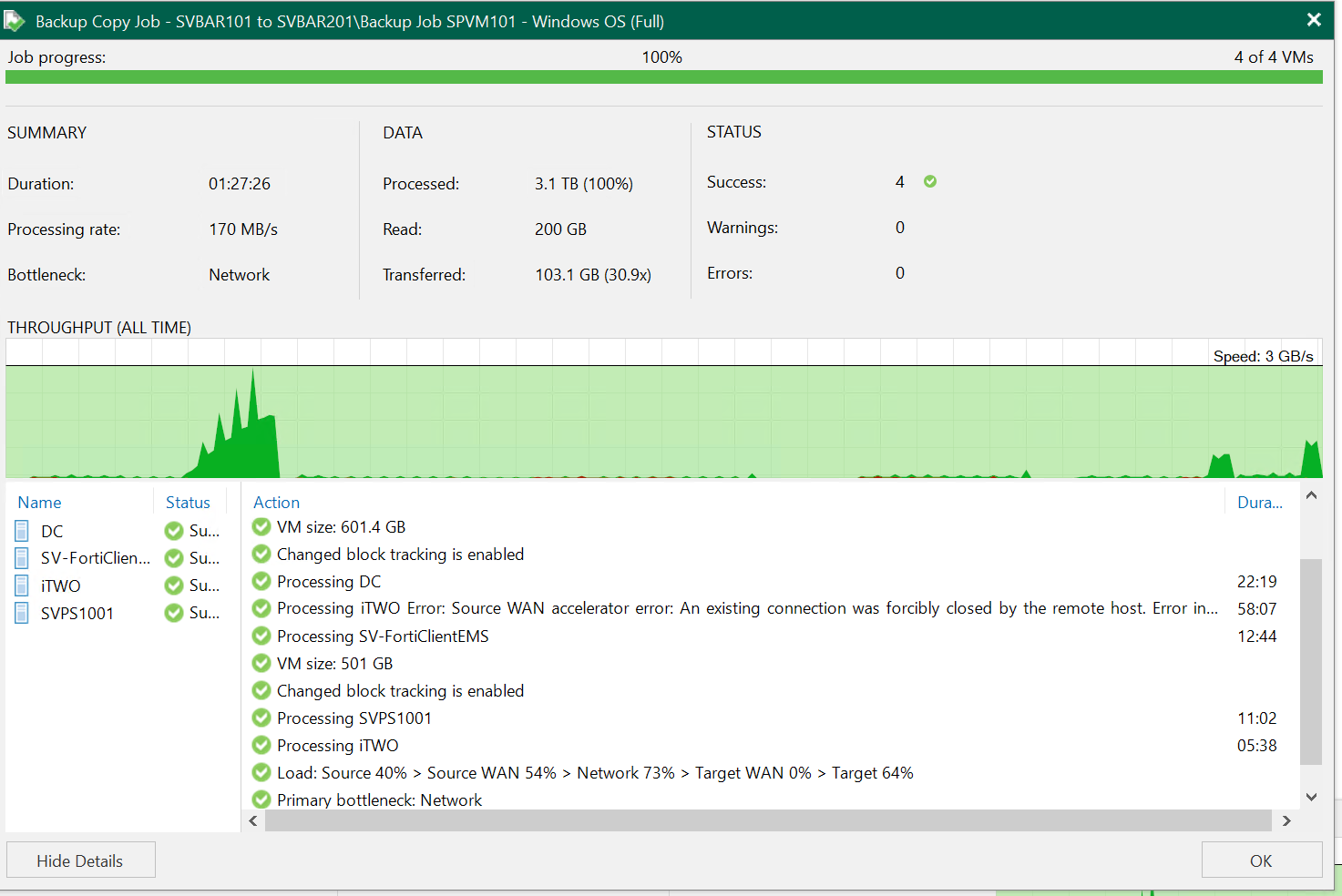
Result of already finished one:
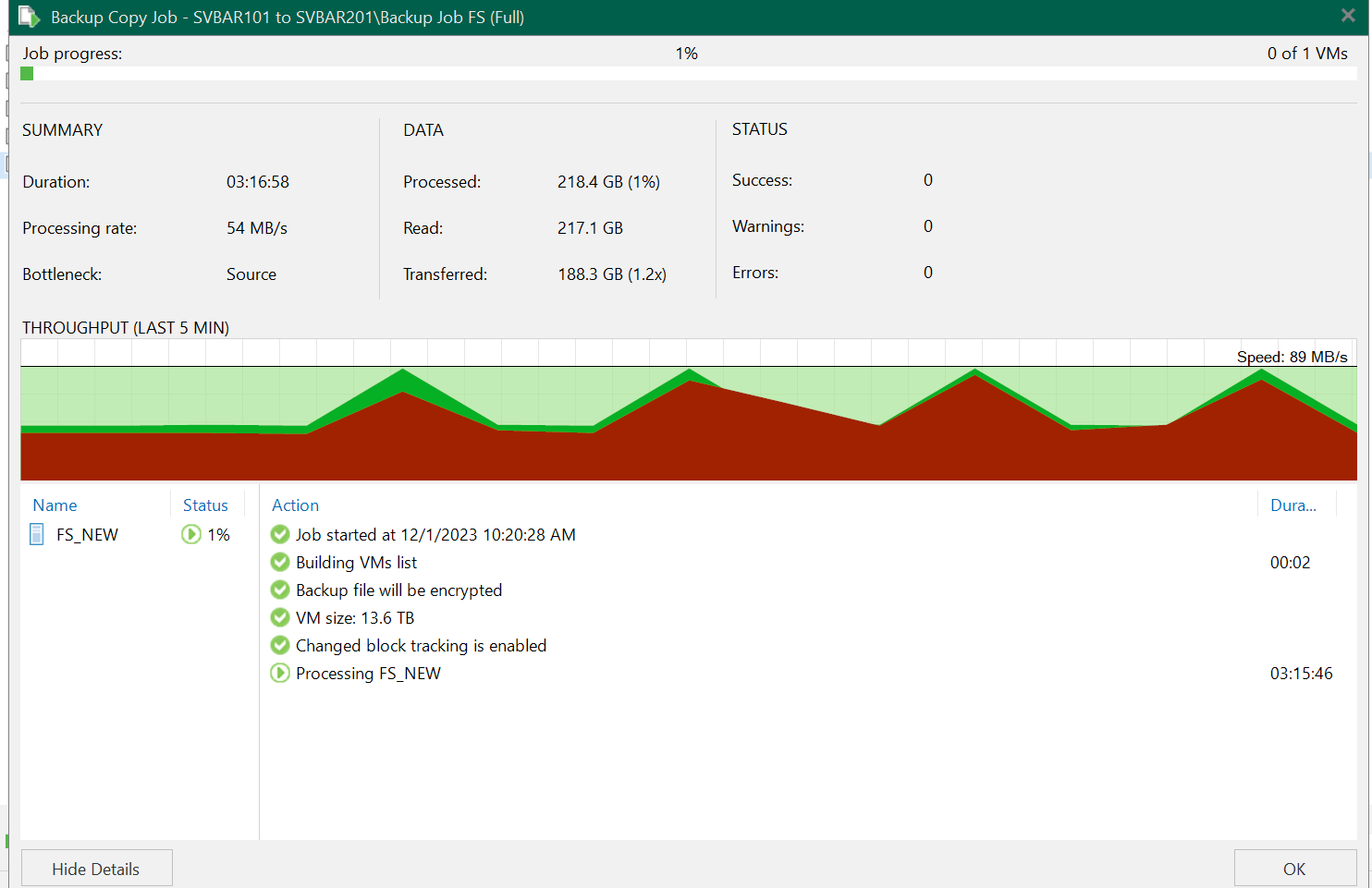
Results of currently running one:

 +1
+1Hello,
I would like to know why are there so many differences in performance of BCJ?
This is all in one BCJ.
Result of already finished one:
Results of currently running one:
Best answer by coolsport00
Performance has to do with many factors - source side storage, network and data path from source to target, WAN Accelerator performance (compute resources, other), and target side storage. There’s no concrete answer to give. For example, you could have latency on the source or even target storage devices based off I/O settings configured in Veeam. As such, Veeam will ‘throttle’ a job (Backup or Backup Copy) based off those settings. Your Proxy and Repository settings have “max concurrent tasks” (Proxy) and Read/Write latency & concurrent task settings on the Repo, which would also throttle back performance of a job. Then there’s network. If your “pipe” is saturated, that can cause performance differences. The only way to be more concrete on where latency/performance issues lie is to test each layer.
Hope that helps clarify a bit.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.


