I'm here to show you a little working proof of concept I put together during the Veeam 100 Summit in Prague last week. It's very much a work in progress, but I'm excited to share it with you.
(video and callout at the bottom for feedback)
Let's dive into the tech stuff and some notes on what we're using.
So, we're making use of the Veeam VBR Rest API, as you will know I am a fan of any API especially when it comes to Veeam.
The prototype is put together using Node.js. It's like the middleman between the frontend and my VBR server and OpenAI. (we're rocking the gpt-3.5-turbo-0613 model).
Although I'm thinking about going with a locally hosted model in the future, especially for sensitive backup server data. But for now, in this prototype and my lab setup, I'm good with this setup, nothing for me to worry about with the few machines I am protecting.
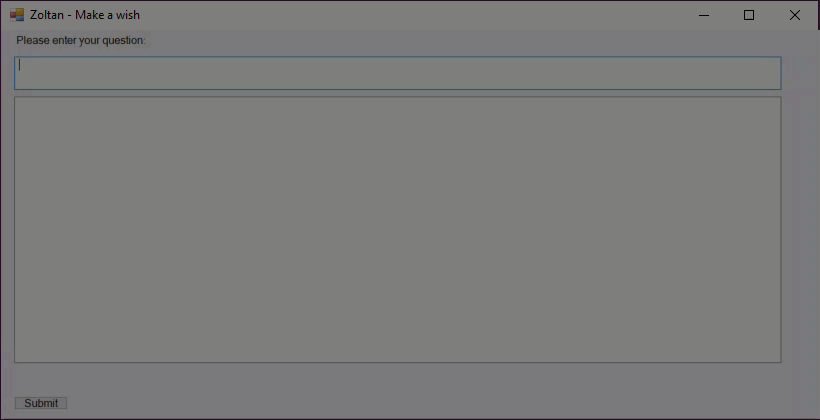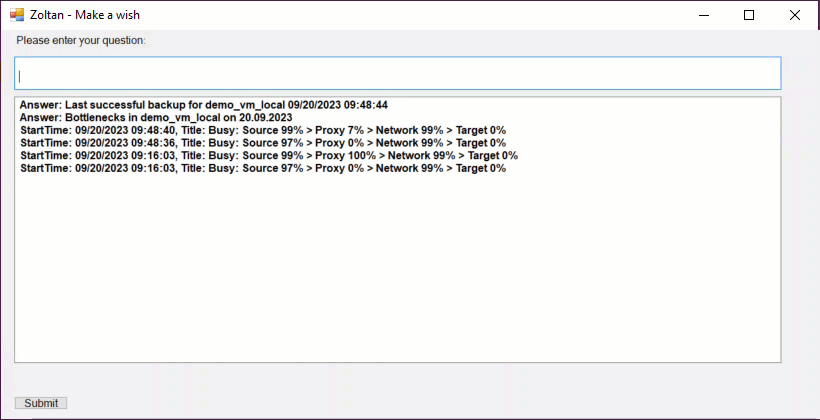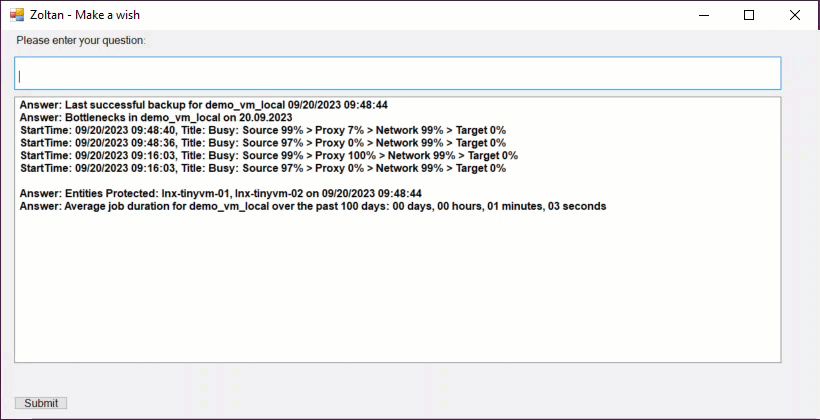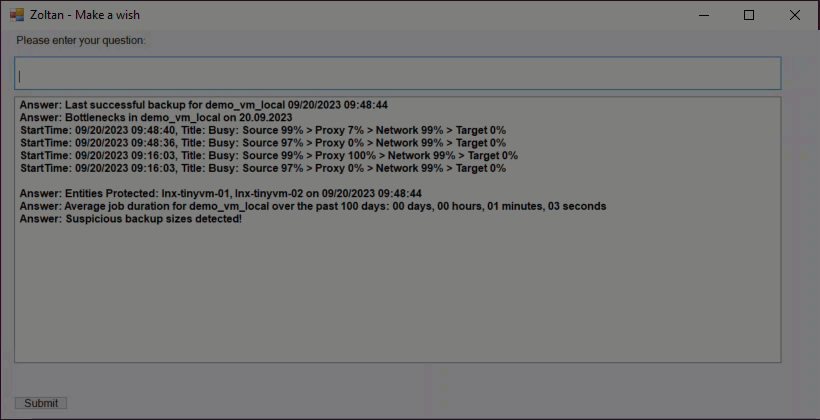
For this prototype, I've focused on Backup Jobs and Backup Sessions, and it chats with four VBR Rest API endpoints to make it happen.
/api/v1/jobs- Grabs all the jobs./api/v1/jobs/states- Fetches job states./api/v1/jobs/${id}/start- Kicks off a job with a specific ID. Don't worry, the ID isn't hard-coded; the LLM figures out the job ID from the backup job info and sends it to this endpoint as needed./api/v1/sessions- Retrieves backup sessions.
Of course, we've got big plans to expand on this, but this should give you a taste of what's possible when we blend real-time data from an API with the power of a Language Model.
Importantly, I am keen to hear from you wonderful people.
- Would you use this sort of thing, and what types of data would you want to see?
- what questions would you ask it?
- Would you let this automate tasks? i.e start/stop jobs, modify jobs, create repositories?
- Would you want it to generate anything for you? code? diagrams?
No promises but good ideas below I might give integrate it and see how well it works.