

Introduction
Object storage vendors all have configuration considerations that must be accounted for as part of the process of designing Veeam backup repositories. Some of these considerations can be limiting, while others simply help dictate architecture decisions. In this post, I discuss on-premises vendor considerations, and how Veeam job settings can make an impact.
To accommodate for vendor specific on-premises Object Storage Device limitations, it is sometimes necessary to adjust Veeam’s storage optimization settings.
Every on-premises Object Storage vendor may express these limitations differently, but it usually boils down to the ability to handle large amounts of object metadata (and therefore number of objects) per bucket and/or device.
In our experience, using larger storage optimization settings (job block size) with on-premises Object Storage devices typically works best. The bigger the storage optimization settings, the bigger the average object size which means less objects to keep track of (object metadata).
Important: It is imperative that you check the Storage Vendor’s recommendation regularly for recommended best practices.
Veeam’s default storage optimization setting is “Local Target” which is 1MB but this can be adjusted as described below (see the user guide and the v11a release notes).
| Local target – extra-large blocks | 8192 KB |
| Local target - large blocks | 4096 KB |
| Local target - Default | 1024 KB |
| LAN target | 512 KB |
| WAN target | 256 KB |
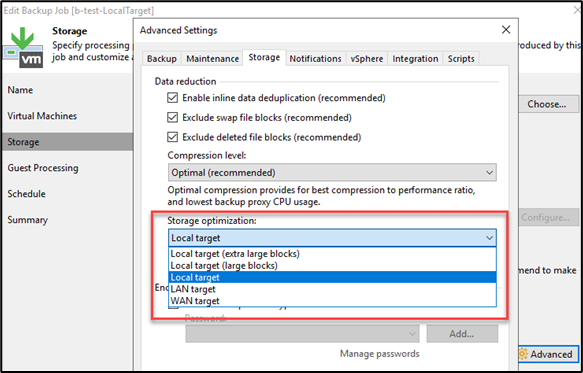
Adjusting the Veeam storage optimization settings will have an impact on an Object Storage based repository in terms of resulting object size, throughput utilization, PUT operations and processing time.
In addition, it is important to grasp the impact larger storage optimization settings have on the size of backup increments.
Impact of Storage Optimization settings
In a previous post, I’ve offered some basic math to estimate the number of PUT operations, average object size, Monthly PUTs, Objects/s, etc.
We will re-use some of this math here to explain the impact of changing the storage optimization settings (job block size) before reviewing some testing results.
Number of PUT operations:
To estimate the number of put operations for a given amount of source data, we must divide that capacity by the Veeam job block size (storage optimization).

The above formula shows that for the same amount of source data, the resulting number of PUT operations should decrease with bigger storage optimization setting (job block size).
Object Size, Number of objects, PUTs per MB, Increments size:
If you consider a conservative estimate of 2:1 data reduction through Veeam compression and de-dupe, the expected average object size will be about half of the storage optimization settings.
For the same amount of backup data, a larger object size should reduce the overall object count and PUT operations.
Less Objects to track mean less object metadata which would suit on-premises Object Storage vendors well.
The table below shows the relationship between job block size, object count and PUTs per MB.
|
| Job block size | Object size | Object count | PUTs/MB |
| Local target – extra-large blocks | 8 MB | 4 MB | 0.125 x N | 0.125 |
| Local target – large blocks | 4 MB | 2 MB | 0.25 x N | 0.25 |
| Local target | 1 MB | 512 KB | N | 1 |
| LAN target | 512 KB | 256 KB | 2 x N | 2 |
| WAN target | 256 KB | 128 KB | 4 x N | 4 |
From a processing time perspective, storing the same amount of source data with bigger objects would require less PUT operations and therefore should complete faster than storing it with smaller objects. This also means that your throughput requirements should increase with the object size.
So why not just set larger block sizes if offloading to an Object Repository? Well, as documented, larger storage optimization settings typically will result in larger size increments.
Reviewing test results
To test the assertions above, I created 5 backup jobs of the same source VMs with different storage optimization settings (block size).
Change rate was simulated by copying a consistent variety of file types to the VMs.
Each backup job targeted a different Scale Out Backup Repository.
I measured offload time, API requests per second, offload throughput, backup size and collated the results on the graph and table below.
As expected, with larger storage optimization settings, the processing time and number of PUTs decreases while throughput increases.
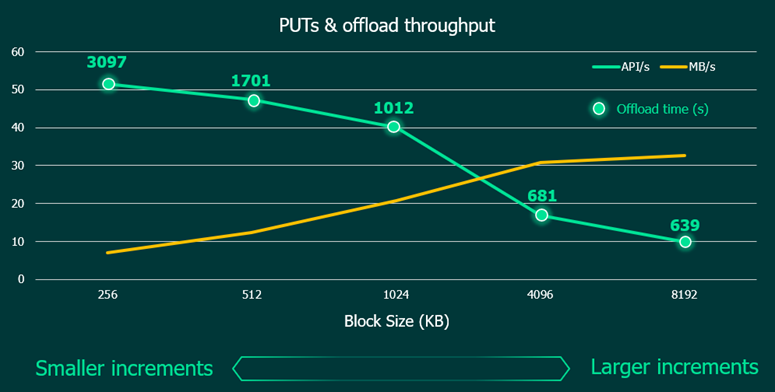
In my home lab testing (i.e. very small data set, few VMs, abnormally low change rate, few restore points), I indeed observed that with larger storage optimization settings, backup size of the same source data increases.
Note: While it was not a huge increase, it was notable enough to realize that with large scale production workload and with a longer retention, the impact on the performance tier’s storage consumption could be quite significant.
Why are some objects bigger than the expected size?
In my testing, I used a mix of text, office, and image files to generate my changes.
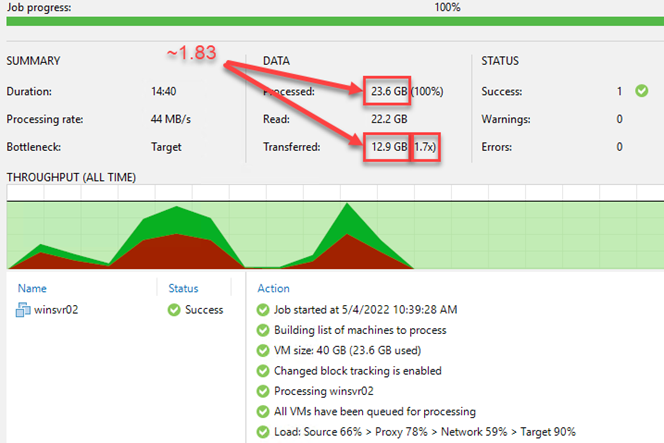
For 1MB (local target) storage optimization setting, I observed an average object size of 562KB which is slightly above the expected 512KB when considering standard 2:1 data reduction.
For reference, the data reduction obtained for this job’s initial Full is 1.7x and if we consider the source data (without skipping pagefile, dirty blocks, …) the data reduction is 1.83x.
By doing some quick math (1024KB / 1.83 = 559KB), we can explain the observed average object size.
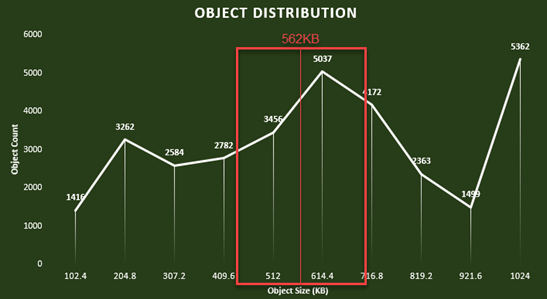
I graphed the object size distribution by increasing slices of 10% of the expected object size below.
You can observe that some objects take the full storage optimization size (1MB in my testing) while others are a lot smaller. This graph simply reflects data blocks’ data reduction distribution.
This is to be expected and the data reduction distribution graphs for other workload types will be different.
The key point here is that if the source data cannot be reduced, the resulting object size will be very close to the Job Storage Optimization settings (job block size) meaning more data to transfer and potentially either resulting in a higher throughput or longer offload time (if hitting bandwidth constraints).
Summary
So what are the key takeaways here? Larger storage optimization settings can provide a workaround for on-premises Object Storage vendor limitations when handling throughput and metadata. With larger blocks, be mindful of larger incremental backups. These may require extra capacity requirements on your performance tier as well as being less agile than smaller backup archives. Hopefully this post offers some considerations on finding the right balance for you.




