Immutable Backup: qualcuno ha provato questa nuova funzionalità ?
Ho letto nell’articolo di VEEAM sull’Immutable Storage che è necessario creare un data repository basto su Linux server.
Qualcuno a qualche informazione in più ? Distribuzione ? RAM ? CPU ? Tipo di storage consigliato ?
Devo ancora approfondire ma intanto volevo sapere se alcuni di voi hanno fatto dei test.
Grazie.
Fabio.
Page 1 / 2
Io lo sto installando presso alcuni clienti ( una decina al momento ) ed in tutti i casi ho usato Ubuntu 20.04 LTS. Per quanto riguarda le risorse RAM e CPU la condizione è variabile a seconda del carico di lavoro esercitato sul repository, ma anche su ambienti molto piccoli, dove il lavoro lo faccio fare ad una VM, mi sono tenuto su un minimo di 4CPU e 6GB ram.
Anche per lo storage adottato, nel mio caso, la condizione varia molto a seconda del carico di lavoro e della disponibilità economica del cliente. Ho usato dalle semplici QNAP per ambienti small business alle SAN full flash per carichi di lavori importanti. Tutte collegati in iSCSI, dove possibile a 10GB.
In generale comunque, si è sempre ben comportata per la parte di immutabilità del dato e in accoppiata con il filesystem XFS non ha mai fatto rimpiangere l’uso del ReFS, almeno fino ad ora.
Se poi desideri sfruttare la tecnologia “Fast Clone” (Fast Clone for Linux Repositories) per velocizzare la creazione dei full sintetici, ridurre l’occupazione di spazio e l’impatto sullo storage, le distro supportate ufficialmente sono CentOS 8.2 e 8.3, Debian 10.x, RHEL 8.2 e successive, SLES 15 SP2, Ubuntu 18.04 LTS e 20.04 LTS. Come RAM e CPU valgono le indicazioni date per il ruolo Veeam Repository: 1 core e 4 GB di RAM per ogni task concorrente (Repository Server Sizing) con una dimensione minima raccomandata di 2 core e 8 GB di RAM. Poiché NFS non supporta la gestione dell’immutable flag, non è possibile utilizzare un mount NFS. Il server dovrebbe quindi essere fisico (per evitare compromissioni al livello di hypervisor) con storage interno o connesso direttamente (via iSCSI ad esempio).
Spero di averti aiutato.
Grazie Raffaele, Grazie Luca
Mi mancavano alcuni approfondimenti e ora ho capito di più. Proverò un’implementazione quindi su server fisico Linux con direct attached storage.
Magari prima in un ambiente di test mio personale.
Buona giornata.
Fabio.
Anzi scusate… approfitto… immagino sia possibile usare l’Immutable storage repository anche per eseguire un secondo processo di backup copy, oppure è disponibile solo per il processo primario di backup ?
Puoi utilizzare un Linux hardened repository come target per backup job, e backup copy job, backup via Agent, backup via VeeamZip, backup via Proxy per Nutanix AHV, backup da External Repository (Azure, AWS, Google). L’immutability non è invece disponibile per NAS backup, backup via plug-in per RMAN/SAP HANA, log shipping: ossia, i backup possono essere indirizzati verso un Linux hardened repository ma non verrà applicato l’immutable flag.
Ciao Fabio,
oltre alle risposte iper-esaustive di Raffaele, ti segnalo questo whitepaper che personalmente ho trovato molto utile:
Per sfruttare l’Immutability con il Backup Copy Job, bisogna attivare il GFS.
Aggiungo, agli ottimi spunti degli utenti e dei colleghi, uno dei tanti progetti del collega Timothy Dewin (l’autore del Restore Point Simulator che tutti noi amiamo e usiamo praticamente ogni giorno ): si tratta di uno script che automatizza e semplifica la creazione di un Linux Hardened Repository.
Grazie Fabio, grazie Luca. Ne approfitto del topic: come mai è stato scelto di non includere Windows Server per l’immutable backup? Si tratta di una scelta tecnica obbligata?
Buongiorno Marco, confermo: è una scelta tecnica obbligata, almeno per il momento. La funzionalità di immutabilità per i backup Veeam è infatti realizzata sfruttando uno degli attributi nativi in Linux, il flag +i (impostabile tramite comando chattr)
Buongiorno Marco, confermo: è una scelta tecnica obbligata, almeno per il momento. La funzionalità di immutabilità per i backup Veeam è infatti realizzata sfruttando uno degli attributi nativi in Linux, il flag +i (impostabile tramite comando chattr)
Processing DC1 Error: write: Connessione in corso interrotta forzatamente dall'host remoto --tr:Cannot write data to the socket. Data size: e16]. --tr:Client failed to process the command. Command: dconnectByIPs]. --tr:event:1: --tr:event:6: --tr:event:3: Processing Cloud Error: Failed to connect to the port r192.168.2.176:2502]. --tr:Failed to connect to target endpoint. --tr:Client failed to process the command. Command: dconnectByIPs]. --tr:event:1: --tr:event:3:
mentre altre VM vengono completate correttamente:
17:39:49 Primary bottleneck: Target 17:39:49 Network traffic verification detected no corrupted blocks 17:39:49 Processing finished at 24/02/2023 17:39:49
non riesco a capire dove sta il problema, qualcuno ha avuto lo stesso errore?
Processing DC1 Error: write: Connessione in corso interrotta forzatamente dall'host remoto --tr:Cannot write data to the socket. Data size: e16]. --tr:Client failed to process the command. Command: dconnectByIPs]. --tr:event:1: --tr:event:6: --tr:event:3: Processing Cloud Error: Failed to connect to the port r192.168.2.176:2502]. --tr:Failed to connect to target endpoint. --tr:Client failed to process the command. Command: dconnectByIPs]. --tr:event:1: --tr:event:3:
mentre altre VM vengono completate correttamente:
17:39:49 Primary bottleneck: Target 17:39:49 Network traffic verification detected no corrupted blocks 17:39:49 Processing finished at 24/02/2023 17:39:49
non riesco a capire dove sta il problema, qualcuno ha avuto lo stesso errore?
Grazie
Ciao @Riccardo Magrini sicuramente aver risposto su un thread vecchio non aiuta nell’ordine delle cose e secondo me il problema è legato al singolo job piuttosto che sulla funzione di immutabilità.
Detto questo…. tu scrivi che altre VM vengono backuppate con successo. Cosa c’è di diverso in questa che fallisce?
Il proxy? Prova a verificare dai log del job ma credo che il problema sia di comunicazione tra il proxy utilizzato e il repository (i classici ping, telnet alla 2502 e verifica che ci sia anche la risoluzione DNS).
Facci sapere.
Ciao, usiamo Veeam Hardened Backup Repository fin da quando è stato rilasciato e ci troviamo molto bene.
Normalmente proponiamo storage server dedicati su base Supermicro, questo ci consente di realizzare soluzioni con capienze e performances molto elevate, interconnessioni a 10Gbita costi contenuti.
Usiamo SO Linux Ubuntu 22.04 LTS e tra i benefici di creare backup repository Linux su filesystem XFS ho particolarmente apprezzato il risparmio di spazio grazie alla tecnologie "space-less" per i synthetic full backups.
Ciao, usiamo Veeam Hardened Backup Repository fin da quando è stato rilasciato e ci troviamo molto bene.
Normalmente proponiamo storage server dedicati su base Supermicro, questo ci consente di realizzare soluzioni con capienze e performances molto elevate, interconnessioni a 10Gbita costi contenuti.
Usiamo SO Linux Ubuntu 22.04 LTS e tra i benefici di creare backup repository Linux su filesystem XFS ho particolarmente apprezzato il risparmio di spazio grazie alla tecnologie "space-less" per i synthetic full backups.
Bell’input quello di Supermicro… hai qualche modello in particolare da suggerire?
GRazie
@Andanet
Ciao Antonio,
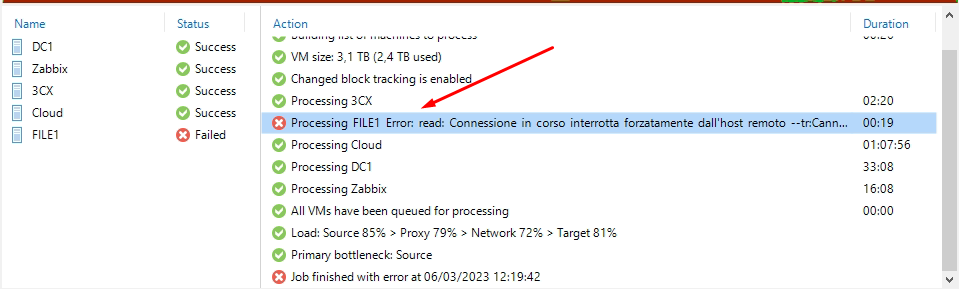
ti mando lo screen del backup, come ti accennavo precedentemente solamente la FILE1 non completa il task riportando come errore “Connessione in corso …..”
e non riesco a capire la motivazione. Il backup giornaliero viene tranquillamente effettuato è sull’immutable che lo riscontro! Grazie
@Andanet
Ciao Antonio,
ti mando lo screen del backup, come ti accennavo precedentemente solamente la FILE1 non completa il task riportando come errore “Connessione in corso …..”
e non riesco a capire la motivazione. Il backup giornaliero viene tranquillamente effettuato è sull’immutable che lo riscontro! Grazie
Ciao @Riccardo Magrini puoi incollare l’errore completo del job?
Sul server File1 nell’ event viwer sistema e security c’è qualche errore afferente nellporario del fallimento del job?
@Link State
l’errore completo dice:
Error: read: Connessione in corso interrotta forzatamente dall'host remoto --tr:Cannot read data from the socket. Requested data size: z4]. --tr:Client failed to process the command. Command: nconnectByIPs]. --tr:event:1: --tr:event:6: --tr:event:3:
sull’event viewer su Sistema e Sicurezza non ho nessun errore!
@Link State
l’errore completo dice:
Error: read: Connessione in corso interrotta forzatamente dall'host remoto --tr:Cannot read data from the socket. Requested data size: e4]. --tr:Client failed to process the command. Command: dconnectByIPs]. --tr:event:1: --tr:event:6: --tr:event:3:
sull’event viewer su Sistema e Sicurezza non ho nessun errore!
nella mia risposta precedente ti avevo scritto del proxy. Ora a meno che quella vm non utilizzi un proxy specifico per il backup…. mi viene da dire che il problema è il guestOS.
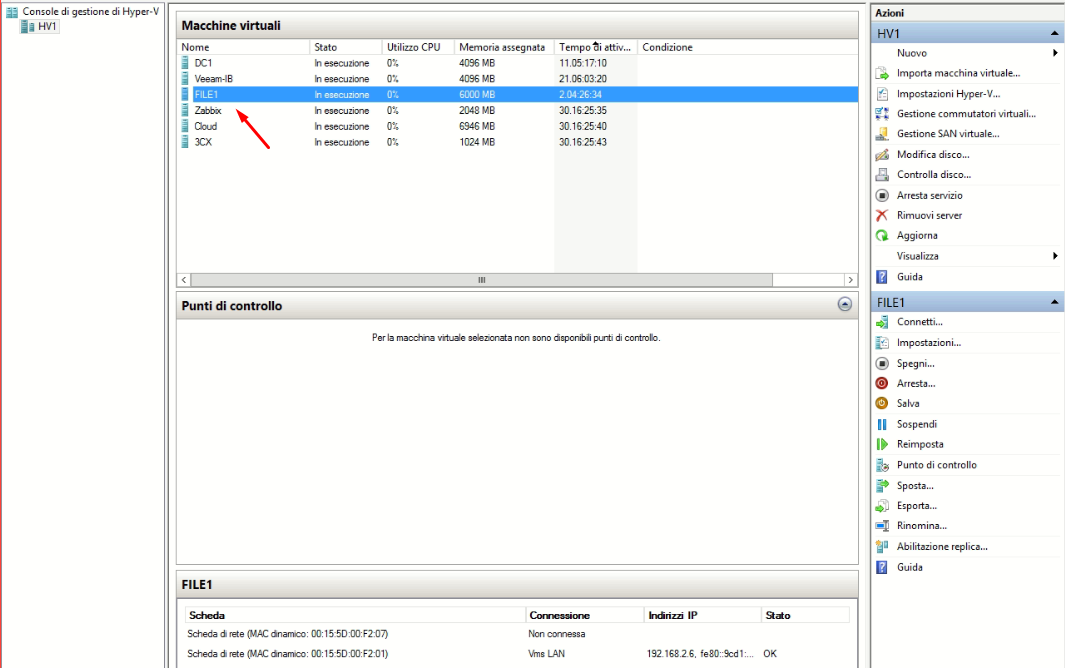
Stai lavorando sui Hyper-V (si vede dall’icona del guest)…. è per caso un cluster?
Credo che la strada migliore sia quella di aprire un case al supporto allegando il support bundle per quel job.
@Andanet
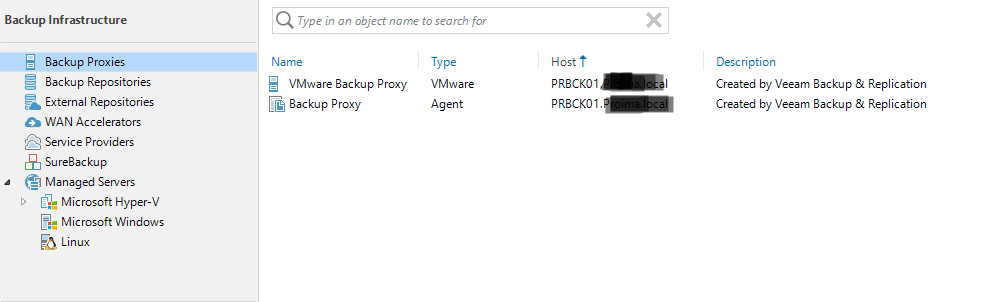
come proxy ho solo questi:
Si l’ambiente è su Hyper-V è non c’è nessun cluster
@Riccardo Magrini grazie per le info.
come hai configurato i proxy su HyperV è differente da vSphere.
Sei in modalità “On Host” oppure “Off Host” proxy?
verso la fine ho visto gli errori ma non riesco a dargli una spiegazione.
non è che il proxy sia necessario o meno per l’immutabile…. è per capire il tutto….a cosa corrisponde l’IP 192.168.2.3? A mio avviso comunque è il momento di aprire un case al supporto.
@Andanet
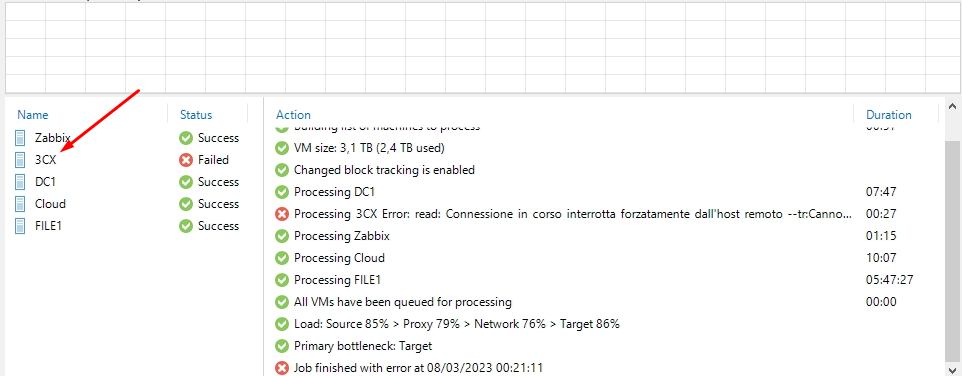
il .2.3 è il server host dove è installato hyper-v, mentre la macchina di veeam è la 2.170. Adesso verificando lo stato dell’immutable è un’altra VM ad avere lo stesso errore mentre la FILE1 l’ha completato: