


Hi,
Another quick hint from the field. I’ve seen on multiple occasions that Veeam can get stuck when moving metadata between cache repositories. I needed to move a batch of NAS Cache metadata to a new location, due to a change in Veeam Backup & Replication v12, whereby now it is recommended that you provision no less than 1GB of cache space per 1 million file versions, per backup job. A bit different to some of the previous ‘best practice’ guidelines of ~4GB total!
As a quick side note, the Veeam Best Practice documentation now suggests 5% of the source data size as your cache size when using object, but I’m sticking to the Veeam Helpcenter documentation’s 1GB per 1 million file versions guidance, as it’s a good minimum for sizing. The Veeam Best Practice documentation doesn’t always scale well once you’ve got TBs of data. For example: At 50TB of data across 25 million files, your sizing with the best practice starts at 2.5TB of cache space. But if you were backing up those files for 31 days and you’ve got a 10% daily change, then you’d need 25GB for your full backup, and 75GB of versions. You need to run your own calculations on what you’ll realistically need. It’s not that the best practice documentation will leave you undersized, but instead it could end up dramatically more than you need depending on job frequency, retention, and change rate.
Anyway, however you’ve come up against the need to move your cache data, you’ve decided now is the time. So, you’ve added your new backup repository to be used as a NAS Cache Repository, edited your file share to utilise the new cache, and you’ve specified for Veeam to copy the data for you. Then… it gets stuck.
This is the exact scenario I came across last week, and when it happens it can be very difficult to determine what has happened. I’ve always found the same behaviour however, all of the metadata sections have been copied across according to the job run, but the ‘Migrating data to a new repository’ step just sits there, endlessly. I’ve witnessed this running for over 30 hours.
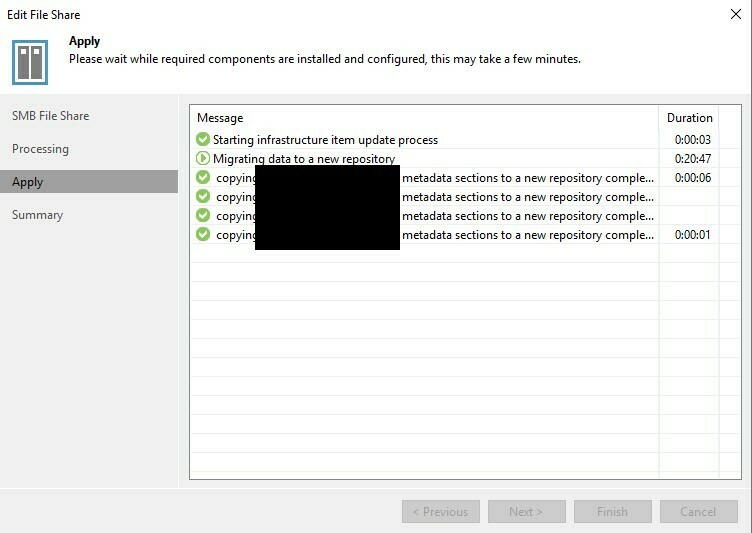
Now, onto the fix! Whilst the window that initially appears for the copy doesn’t have a ‘cancel’ option to revert this change, it is still possible. Click the x in the top right, and then navigate to “Inventory > Last 24 hours” within the Veeam Backup & Replication console, and you’ll see a running job called “File Share Update”. You’ll have the option to stop this task made available by the actions section at the top of the UI, or you can click on statistics and then choose the text labelled “Cancel restore task”. In my case the job finished immediately with a failure.
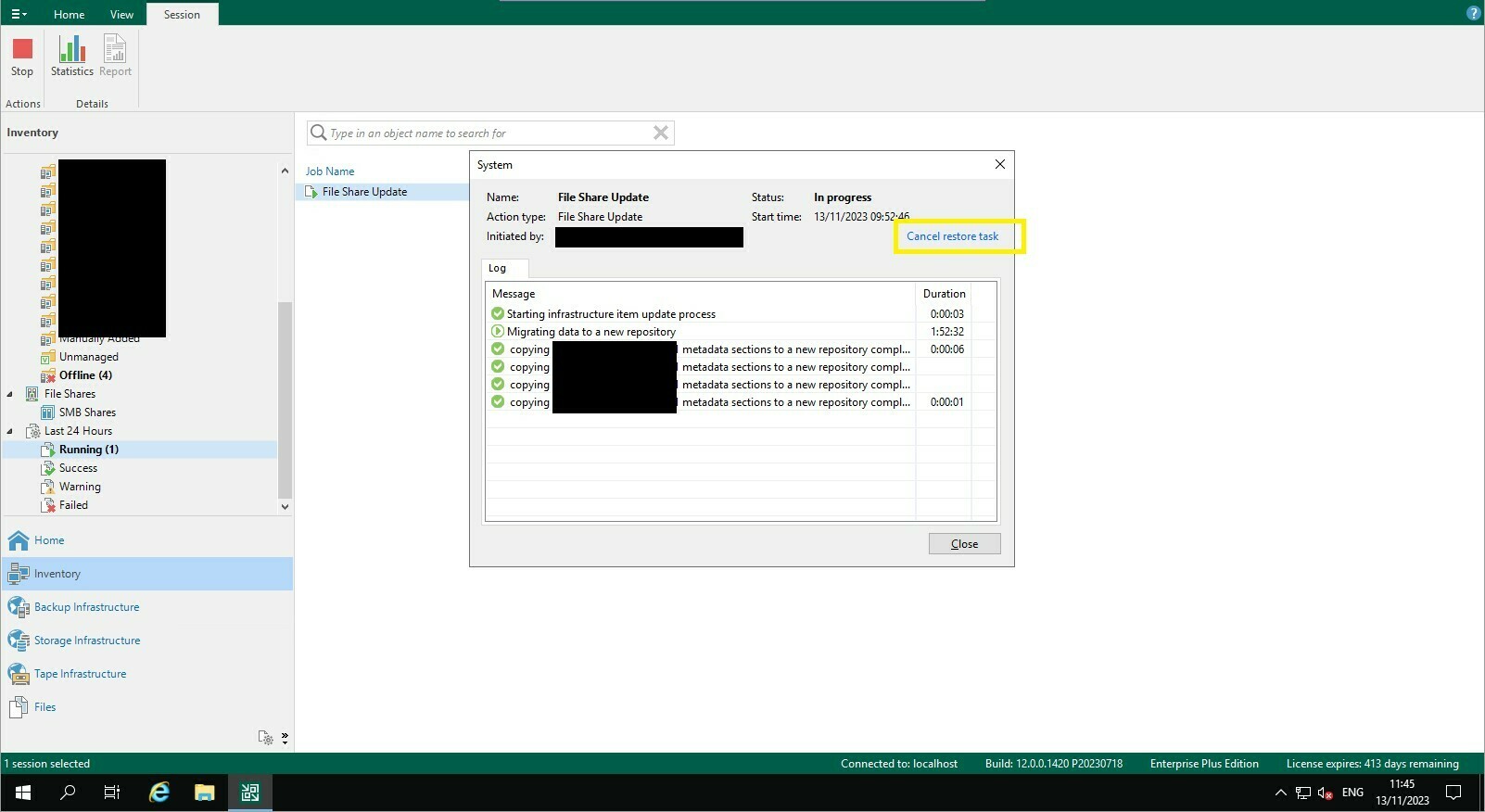
If you're wondering what happens to the file share in this case, the cache repository selection is reverted, and as the cache metadata hasn't been deleted, the job can continue as normal. I had a couple of file shares that got stuck in this state and when cancelling and restarting them, they finished in seconds.
If retrying doesn't fix this for you, I've noticed that when it gets stuck, all the data has copied, but it seems like some kind of race condition triggers and the application is sat waiting for a thread that already finished. If you have continuous problems with this, it is fully supported to manually copy the metadata to the new location, and then perform the same 'Edit File Share' process to change the cache repository location, and you can instead select 'Attach' to utilise the manual data copy in the new location. If you do this, please just ensure you've disabled the backup job(s) utilising this share, so that you avoid any issues with the cache data being updated between copy & repointing of the cache repository.
Hope this helps!


