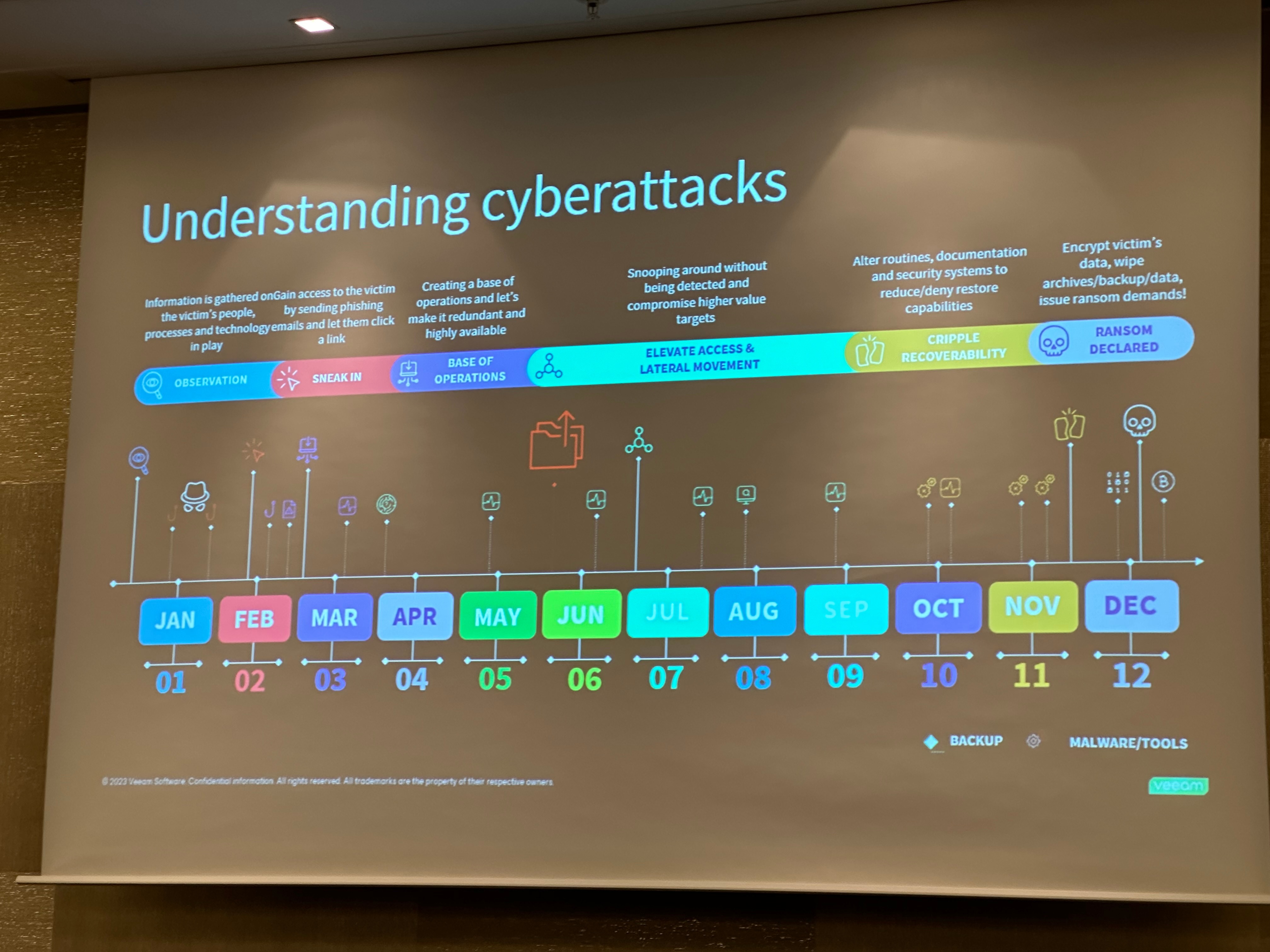
We start the day with

First up is Jorge talking us through the Veeam ONE Threat centre.
Jorge talks us through the data platform scorecard, made up of the following four contributing components:
- Platform Security Compliance - This is driven by the VBR Security & Compliance Analyser (Formerly known as the best practice analyser)
- Data Recovery Health - This score looks at backups marked as suspicious/infected, you should hopefully see a 100% health when you first deploy this
- Data Protection Status - This score is based on the percentage of protected workloads vs unprotected
- Backup Immutability Status - This score is based on the number of workloads that are not compliant with the immutability target.
Within each of these widget sections are call to actions for a related report to provide drilldown information on the appropriate topics
Each of these widgets have options to include/exclude settings for example:
- Data Recovery Health can choose to include & exclude specific backup repositories
- Data Protection status can filter to specific workload types such as VMs, Computer, Unstructured Data, Cloud Instances, and Enterprise Applications, but additionally against a globally defined RPO to be considered as ‘protected’ ensuring that a 6 month old backup doesn’t qualify as ‘protected’
- Backup Immutability Status - This is very flexible, includes not only the ability to filter resources, but also define a minimum immutability retention policy to align infrastructure against.
There is a world map and you can assign locations to backup repositories tied against a geo-search for cities across the globe!
The threat centre also contains an RPO anomalies widget to show up to the top 30 anomalies for RPO within your organisation, and an SLA compliance heatmap for individual workload success vs failure backups and you can define an SLA target against. The SLA compliance heatmap can be set to reflect up to the past 180 days for SLA compliance.
Veeam ONE Client
There are new reports for unstructured data compliance (NAS + Object Storage), you can look at compliance against RPO, but also compliance against protected data percentages. For example a backup job that is successful but only protects 3% of the files, isn’t really a successful backup job.
Veeam Malware Detection
Over to Roman we’ve got multiple malware alarms appearing within Veeam ONE such as:
- Veeam Malware Detection Activity State
- This rule raises an alarm if malware detection is disabled within VBR
- Potential malware in backups
- Tracks infected, suspicious, and even marked as clean within the alarm. So even if marked as clean, Veeam ONE will still highlight this.
- Potential infrastructure malware activity
- Monitors for infrastructure activity of infected workloads, and we automatically, or by approval, the ability to disable VM network, run scripts, or switch VM network such as to an isolated network
- Veeam malware detection exclusions change tracking
- Tracks if any exclusions are defined for malware detection
- Malware detection change tracking
- Tracks if any changes have been made to Veeam settings for malware detection such as decreasing sensitivity to malware detection entropy
Another really cool feature is the ability to perform actions against your production environment based on alerts, examples provided were disconnecting the VM from network, migrating the VM’s network to an isolated network, or running a script.
Security & Compliance
Roman next talking about each security & compliance alarm and the flexibility of control over the rules if you needed to exclude specific best practice rules (please only do this if you have a good valid reason!)
The backup security & compliance reports are pretty cool, if you’ve got multiple VBR instances you can choose to group your reports by rules or per VBR server!
Enhanced Alarm Lifecycle
Over to Kirsten now and we’re hearing about the new ability to output alarms to ServiceNow and/or Syslog. Setup is extremely easy, we can add this via the server settings menu, with two new sections added to the hierarchy, one related to each of these. Alarms won’t be pushed out to syslog/ServiceNow by default, ensuring that only the alerts that you desire, are pushed to ServiceNow. Communication with ServiceNow is two way, meaning that resolving cases within ServiceNow can resolve the Veeam ONE alerts too.