

Hello guys 😄
Hope everyone are well ! In my side I'm in vacation 🤙. I wanted to share with you some tests done with the beta of Veeam v12 (build 12.0.0.817) and the incredible new feature backup directly to Object Storage.
Object Storage
For my test I used Wasabi as cloud object storage. You can find really great posts about Wasabi:
Wasabi is now available in the list of providers when you want to add an object storage repository

We have less information to enter, it's appreciable
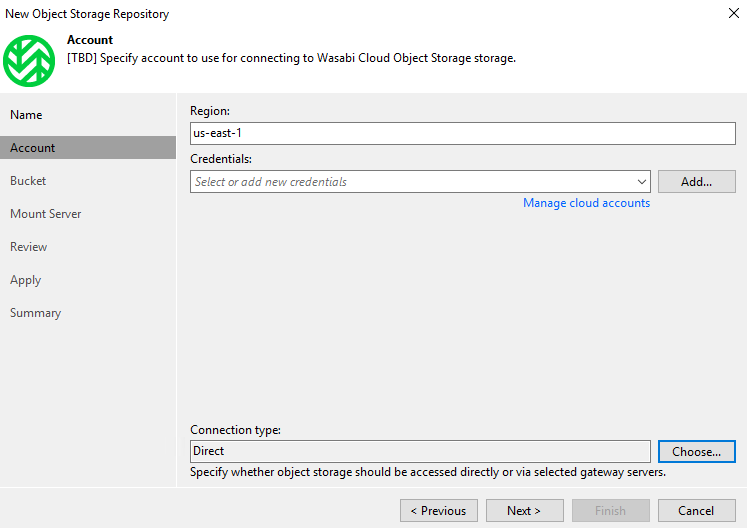
You will find your repository with Wasabi Cloud Storage Type.

Backup Job
The advantages of this kind of backup are multiple:
- Financial: you can use on-prem object storage, object storage can be cheaper than SAN
- Built-in durability & reliability
- Reduce hardware to manage
Let's take a look at the setup, because there are technical side effects.
As usual you select your repository, the GFS part still available and you could configure a backup copy job if necessary
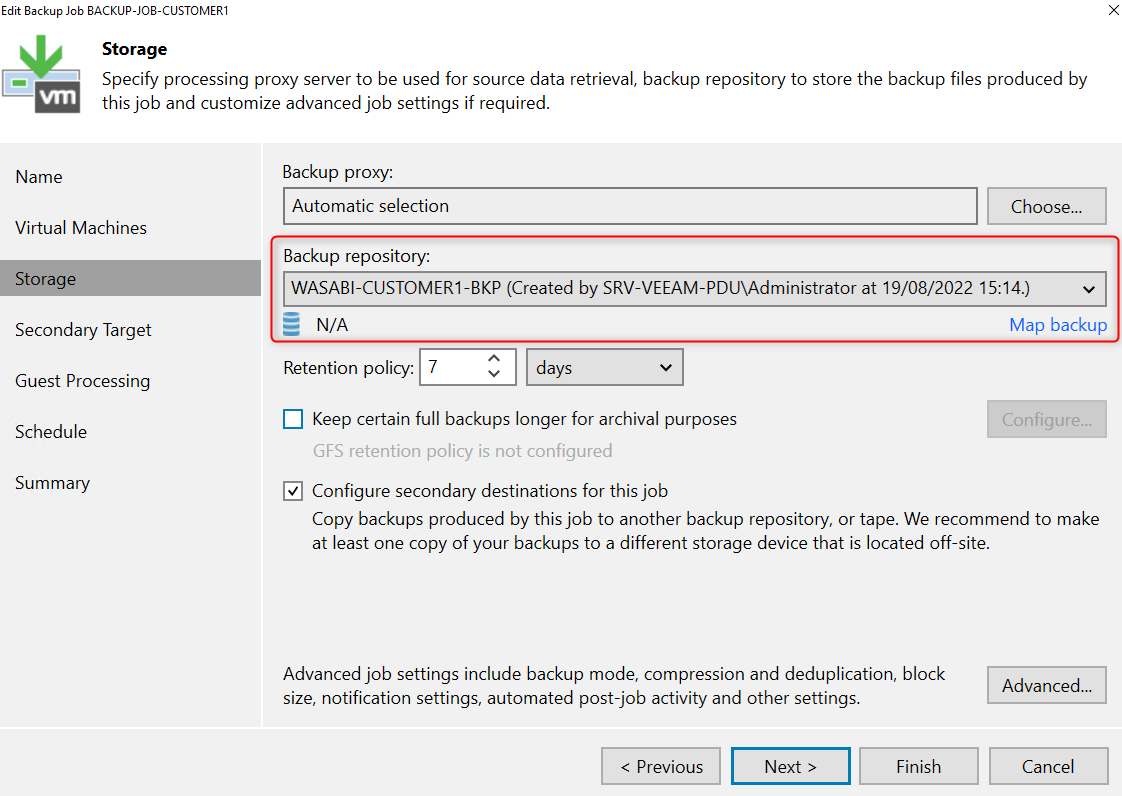
In the advanced options, it’s simplified ! Bye backup modes, you just have the possibility to create an “active full”
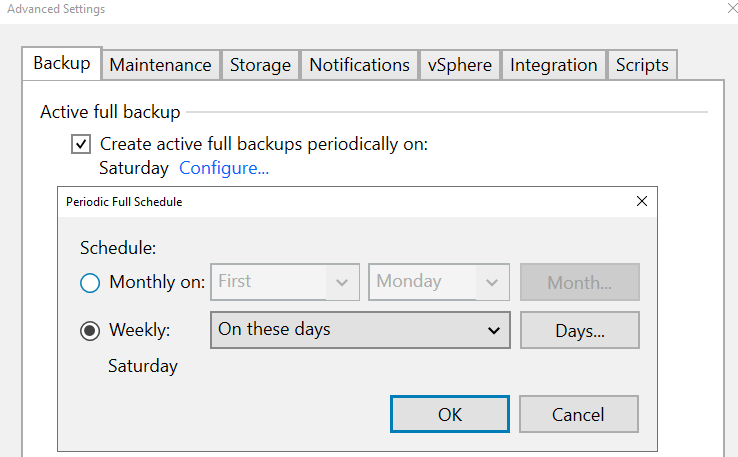
It's due to how object storage works. I haven't test to configure the active full option but I presume that the job will transfer all blocks and not only the news ones.
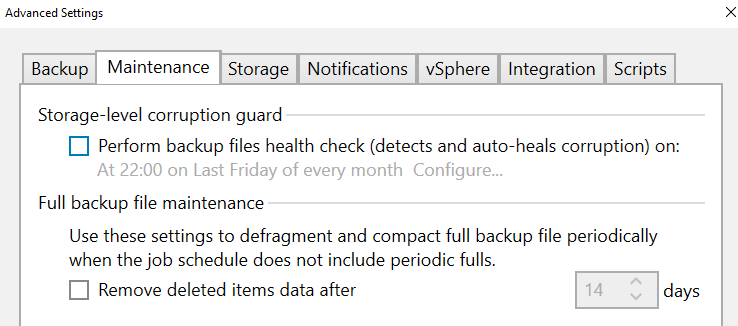
I don’t know why the synthetic mode is not available, like GFS points are still possible.
The defragment compact full backup file periodically option disappear too
After that my job ran I thought to find my backup under “Object Storage”, but they are in the “Disk” section. Maybe this will change in the release version.
Backup Copy
Here we don’t have a lot of difference, the two copy mode are available (mirroring/pruning)
I just test to backup copy an object storage backup job to another bucket and it works perfectly.
As for the backup job, the files are visible under “Disk (copy)”

Use-cases
There are multiple, here some ideas:
- Backup to on prem object storage
- Backup copy jobs to object storage, I ll probably review for some of my customer the externalization to object storage with backup copy jobs. With a SOBR it's not possible to change the retention configured in the backup job so if you have a long retention on-premise you will have the same in S3. Backup copy job direct to S3 will simplify some architecture and in bonus the GFS points ll be normally protected for all their retention period.
- Agents running in Cloud or in home-office
- Backup direct to cloud for archival
- Backup configuration to cloud. Protecting the backup configuration is really important, I always recommend regularly exporting to an offline media this backup.
With the possibility to backup it directly to the cloud we profit of durability and reliability (the "11 nines"). A backup copy task for this job for me is still missing
Don’t hesitate to share some other ideas!
Support
It will be possible to use direct to object storage for:
- Virtual machines backup (VMware,HyperV,AHV...)
- NAS backup
- Backup copy
- SQL, Oracle
- Configuration backup
- Veeam agent
Bugs?
Currently when I want to delete a backup stored in the object storage, the task run indefinitely. The files is deleted but I have to close/reopen the console to the the task in success.
Conclusion
A real game changer, this will allow architects to have many more design options. This will simplified some requests, in particular the fact to avoid the use of SOBR to externalize.
Do you expect this functionality and if so for what needs?
Cheers!

