

I wanted to share a couple Veeam errors I experienced on my Replication (DR-side) server after I replaced server hardware. Not sure if anyone has experienced either of these errors, but they were quite frustrating to work through. Let me know if you had a similar experience/occurrence and what you did to resolve it. Maybe what I share here will help someone.
As I was replacing hardware in my DR side vSphere Clusters, on my VBR server, I would perform a vCenter rescan to make sure VBR would see the new Hosts and my Replication jobs would run successfully. Because all the tasks involved with replacing h/w is time-consuming, I was only doing 3-4 Hosts a day (took 3 days for 10 Hosts), so I had to do this rescan several times. I think I only verified 1 or 2 jobs out of around 12 I have, but they run good. On the 2nd day, I noticed 1 of my jobs failed. The error shown was below:
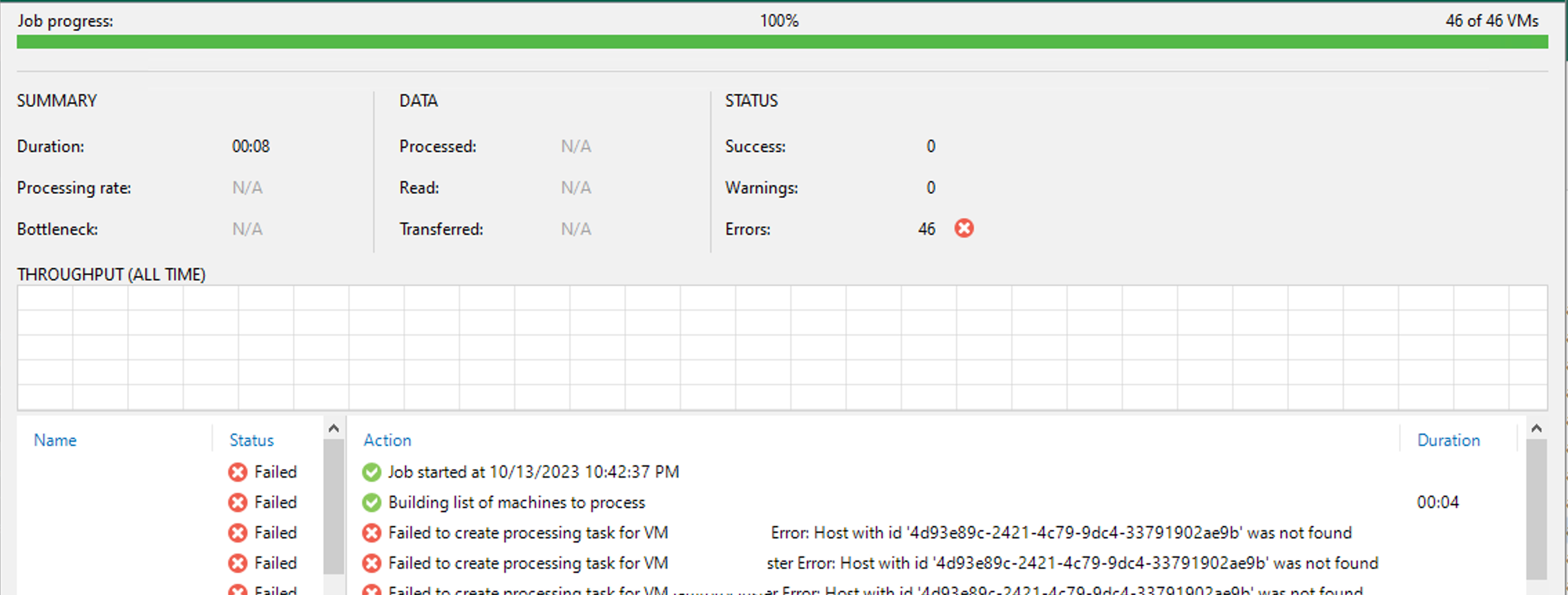
So, it appeared to me like Veeam didn’t actually update all references to any of my old Hosts and their associated ID from the DB. Another thing I noticed → when I went to look at my Repilcation job settings, well….I couldn’t. I got another error when trying to go to the job > Edit:
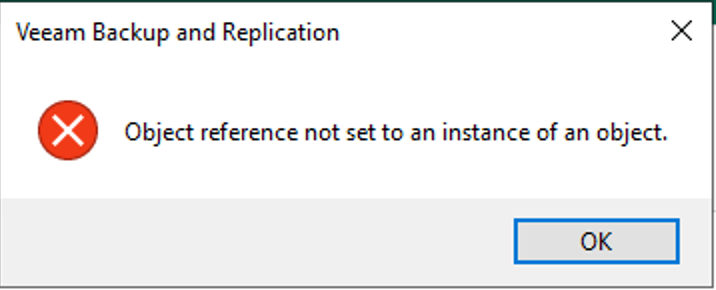
I have received this 2nd error before. On my Backup jobs, because I use BfSS, I have certain Repositories on certain physical Hosts, which I also use as Proxies (i.e. “combo boxes”), so I explicitly assign the Proxy in my Backup jobs. If you either temporarily or permanently remove the Proxy component from the VBR server, you can get this above 2nd error if you attempt to go into your job settings. If you re-add the component, then you should be able to again get into your job settings. An easy way around this error is to configure your job as Veeam recommends → by Automatically assigning Proxies.
The odd thing about getting this error on my Replication VBR server is I have all my jobs configured to do Automatic assignment of Proxies. So, I’m not sure why this error surfaced.
After contacting Veeam support when all my troubleshooting and reviewing various Internet articles and Veeam forums posts failed, we were finally able to come up with a solution, which is just short of a full server rebuild:
- Document VMs you have in your Replication job, if you don’t already have this anywhere. You may even be able to retrieve a list of your VMs via PoSH and place them in a text file, I just haven’t looked up a command to do this (yet 😊).
- In the Console > Replicas node > Ready section, search for each VM in the job, rt-click it and select Remove from configuration. Another option is to do CTRL+Click each VM so you can get them all at once, then click the Remove From button from the Ribbon and select Configuration. NOTE: this process does not delete any Replicas you have in vSphere, and this is a good thing. It only removes the Replica reference from the DB.
- Once done, go back into the Jobs section and delete the Replication job, then recreate it. Hopefully you also have your job settings documented somewhere. If you don’t have this anywhere, I recommend doing this now so you have it in case a situation like this happens and you need it.
- In the Create Replication job wizard, select the Replica seeding option so you can map your VMs to the Replicas still in vSphere. This is done in the Seeding section of the wizard. Configure all your remaining job settings and click Finish at the end.
- You should now be able to run your jobs successfully.
Because of the tediousness of this process, and to make sure all worked as expected, I only did this process 1 job at a time. A couple things to be aware of: when your jobs run, it can take a while for the VBR server to “Discover replication VM”. I don’t have an answer as to why this is, but it can take a while -- anywhere from a minute to many minutes. Also, CBT gets reset so it’ll take a while for each VM to get replicated. Good thing is you have the VM Replica still in vSphere, so it shouldn’t take as long as it would if no Replica existed.
One last thing I want to share some may be asking: why didn’t I just find the Host ID reference in the DB and delete it? Well, I tried that too...from a few DB tables I thought it would be in - the host table and physicalhost table, but the ID was not found when I tried searching for it. Support didn’t offer any further assistance in attempting to manipulate the DB. Maybe they thought doing so would crash the server...I don’t know.
I wonder if Veeam has a recommended process when doing hardware refresh so this problem potential is mitigated or at least significantly reduced. Anyone know of any?...

