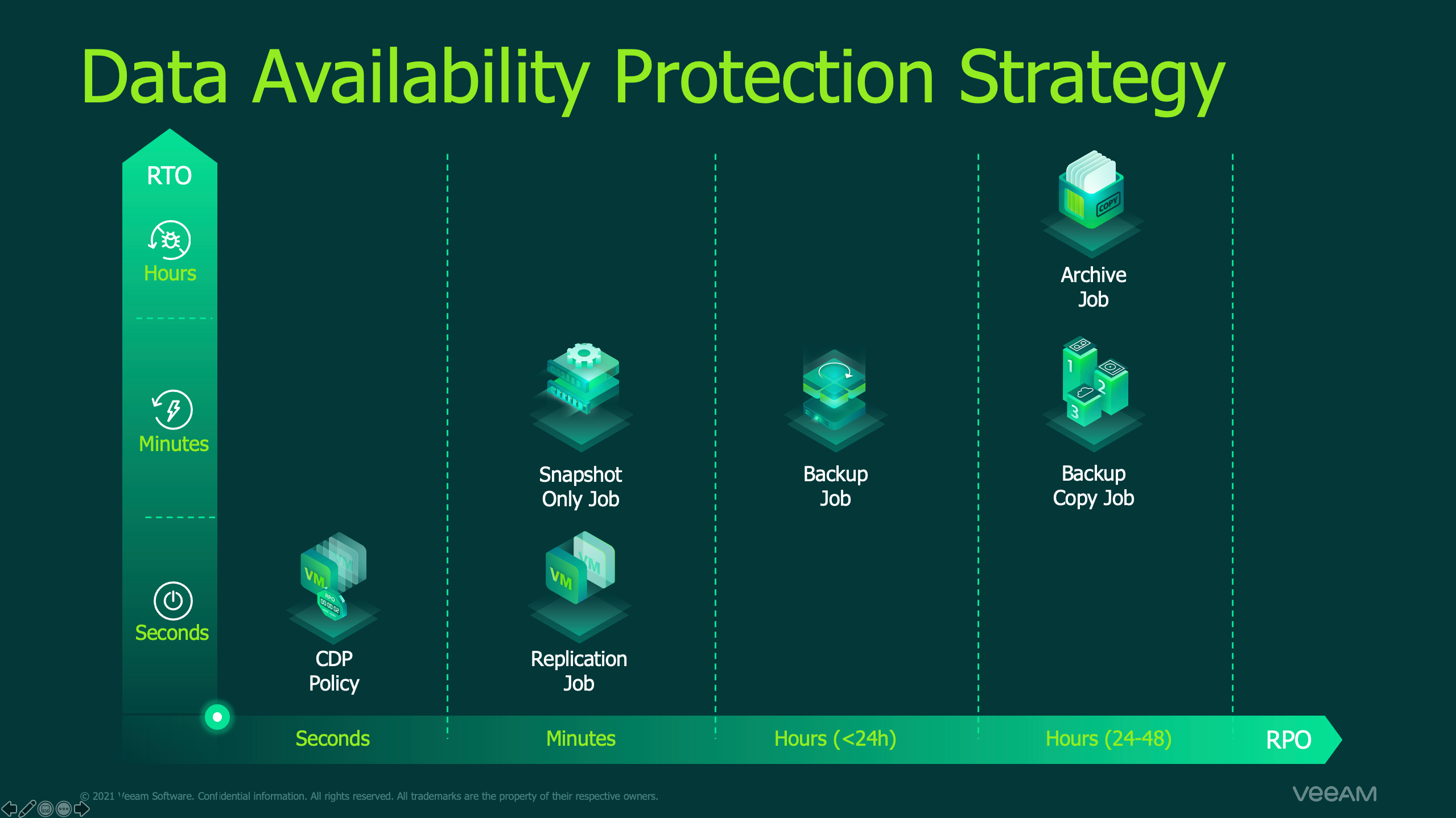
Today, I’d like to talk about creating and scoping realistic and enforceable RPOs and RTOs for your Business Continuity (BC) and Disaster Recovery (DR) policies and Service Level Agreements (SLAs) within your organization. As every organization will have different requirements the focus of this blog post is on general considerations for shaping your policy.
Additionally this blog post is focused around policy design as opposed to backup technologies and should be vendor agnostic for the most part, though where I am aware of features from my backup solution of choice (Veeam of course!!!) I have referenced improvements that solutions such as Veeam can bring to the process.
The assumption is made that you’re already aware of the applications, operating systems and data within the organisation/environment you’re designing these policies for.
Step One: Define Recovery Priority
Before we start to consider recovery point objectives, we should consider the recovery time objectives of our workloads. It is no good bringing up a SQL Server that requires no more than 5 minutes of data loss and recovery within an hour, if the authentication to access the database is handled by an Active Directory domain that is going to take another 4 hours before it has been restored from tape.
Define a list of your workloads grouped and organised by how fast they must be recoverable, then reference any known dependencies on other workloads and sort the data again with dependencies referenced. This will form the basis of what is acceptable for data locality and the underlying storage performance required to support these objectives.
In summary, the higher the recovery priority, the lower the RTO will be required relative to the rest of your workloads.
Step Two: Identify Your Risks
RTOs and RPOs don’t need to be universally defined, different disasters can be remediated with differing levels of response and effort required. Consider these three scenarios:
- Accidental deletion of an important virtual machine
- Ransomware infection
- Building burned down
These scenarios all require different amounts of effort and therefore different amounts of time to recover from.
In our first scenario, we can utilise technologies for rapid recovery such as replication, storage snapshots or even Veeam’s Instant Recovery and Continuous Data Protection (CDP) technologies to minimise delay for our return to production, yielding a realistically low RTO.
In our second scenario, more blocks have been changed on our storage but again utilising the technologies referenced in section one could prove useful, so they meet a similar RTO at first glance, however if your primary backups weren’t immune to the ransomware threat, you could be looking at recovering from a slower backup tier of data, impacting your RPO & RTO negatively.
When we consider our third scenario, everything could change. If a building has burned down, that could likely spell the destruction of backup data or storage snapshots locally on site. You may be fortunate enough to have rapidly accessible offsite backups or replicas and as a result your RTO may not change dramatically, otherwise if you may have had to go to Tape/USB and are now trying to source new hardware, or recover your backups to a public cloud vendor on a residential speed internet connection, this should be considered within your RTO.
With the threat landscape constantly evolving it is near impossible to plan for every eventuality, but by grouping disaster types you can create a clearly defined list of pre-approved response strategies and ensure that data recovery is a Business As Usual (BAU) process.
If you require inspiration on threats to protect against and how to protect against them, consider the 3-2-1-1-0 best practice rule. You should have a minimum of three copies of your data, across at least two different media types, at least one of these should be in an off-site location, at least one of these should be offline/tamper-proof and finally there should be zero recoverability errors, which we’ll come to later on. Remember, the 3-2-1-1-0 is a minimum best practice, if your business justifies the need to go above and beyond this, or you already have the resources to go further, don’t stop when you reach it if you can do better.
Step Three: Separate Desirable and Required RPOs
Downtime and data loss are becoming increasingly unacceptable within organisations, but IT budgets aren’t growing at the same rate to facilitate these demands, it is important to separate early on what an organisation “wants” from what it “needs”. You have a finite amount of compute, RAM, disk capacity, disk IOPS and bandwidth. Look at what is required to meet the minimum RPOs acceptable by your organisation, if these can’t be met with your existing resources, you are setting yourself up for failure and will need to look into changing your approach, which we’ll discuss shortly. Once we identify the gap between what is wanted and needed, we can start to bridge that gap.
Step Four: Layered RPO
Just like we planned for different eventualities back at step two for our RTO, we should plan for different disaster types within our RPO. We should breakdown our workloads into individual segments of recoverability requirements. As an example, a modern SaaS application will likely contain (simplified):
- A load balancing/Web Application Firewall (WAF) solution
- Web Servers
- Database Servers
If we now review what we’re dealing with here, we will have different RPO tolerances.
Firstly with our load balancing/WAF solution, this will likely contain a static configuration that only changes when updated on a monthly maintenance schedule, potentially with some frequently updated IPS results that are downloaded from the web and easily obtainable. As a result our RPOs can be quite high as the data from two to three weeks ago could still be perfectly valid, or rapidly brought back into production with just an IPS signature update.
Now we move to our Web Servers, you may be thinking it’s the same again, likely just static content. This could be true, but it could also be on a more frequently updated basis, so we may have need for a more aggressive RPO over our load balancer but otherwise not require much change. On the surface this would be correct, but now lets change our view point to an Information Security Consultant and look at what this Web Server contains, if we consider the recent Microsoft Exchange Server zero days or even the compromise of Stack Overflow, log files were a tremendous help in determining malicious activity, so whilst we could restore the application with an acceptable RPO, we may wish (or even be required by legal/contractual agreements) to have an even more aggressive RPO for these log files, to prevent malicious actors covering their tracks or losing forensic data for post-intrusion analysis. For this we may choose a create a second job to protect this important data, this could be a job focusing on the frequent backup of a log drive, or even using a resource such as Veeam’s Agent for Windows/Linux to frequently backup the data and send off to a backup repository.
Finally, we need to protect our database servers, at first glance we may be tempted to create an extremely aggressive RPO policy to protect against any data loss, however, lets apply our lessons learned from step two here and consider the risks we’ve identified and how best to mitigate these in our RPO requirements. We could look at a frequent CDP policy to protect our data into an off-site location for rapid recovery with near zero data loss, but what about database corruption? CDP’s short-term retention is focused on crash-consistency as opposed to transaction-consistency, which is of huge importance to databases. To protect from this risk we can reapply our strategy for protecting the web servers, we can protect the underlying server operating system and configuration at an infrequent level such as nightly backups, but then complement it with technologies such as SQL Log Shipping to create aggressively low RPOs for our databases themselves.
Step Five: Verification
Now we have a draft taking shape, we know what threats we are planning to recover from, we have assessed the segments of our workloads requiring more aggressive RPO and we have our overall recovery priority list. What’s next? Testing!
Before you commit to an RPO or RTO, it is crucial that you test and benchmark your ability to adhere to the recoverability scenarios you’re building your policies and your Service Level Agreements (SLAs) around.
These results will become the foundation of any business justifications for any projects required to meet the business needs being asked of you. If you managed to meet the requirements defined, well done! You can sleep a little easier knowing that your system can meet these needs and now you can expand your scope from the business minimum requirements to the business’ desired recovery posture.
If you didn’t manage to meet the requirements, you now have a lot of metrics and real-world results to highlight your bottlenecks (as we discussed in step two, you have finite resources!) and where you can best implement change to improve this. You may have even found yourself having to revert to step one as you found a previously unrecognised dependency in your recovery priorities!
Before you go running off to the stakeholders with your results however. I want to discuss one last step that is far too frequently overlooked.
Step Six: Fault Tolerance
Faults happen, it’s a fact of life. If you look at vendor solutions available for any enterprise grade technology, redundancy is built in, RAID arrays with multiple disk fault tolerances, servers having spare power supplies, redundant network switches, and even redundant geographic data centres. Where am I going with this? I’ll keep it simple!
Factor in redundancy when designing your RPO/RTO policies. Just like any production workload can fail (you’re designing this document after all!), your backup processes can fail. A Windows Update could trigger a reboot on your backup server and cause your backups to fail. A network interruption between your data centres could temporarily pause replication, a failed disk could cause your RAID array to be rebuilding its array onto a new disk causing a reduction in IOPS capacity.
Just like most organisations have a minimum of N+1 resiliency in their production, I recommend at least N+1 resiliency in your RPO/RTO policies. If your RPO policy states you can’t tolerate more than 24 hours of data loss and you’ve chosen to backup your workload just once a day and VSS fails causing your backup job to fail, you have just violated your own policy/SLAs. However if you were backing up twice per day you now have 12 hours to fix the issue and trigger another backup job run to ensure you maintain your RPO minimum and adhere to your commitments to the business.
Referring back to step five, if when you validated you were just scraping by with adhering to the business required RPO/RTOs, any interruption could put you in violation of this, likewise if you’re not meeting your business’ requirements, don’t design your replacement solution around just meeting these minimums, set the bar higher! Ensure a realistic buffer to allow time to react to environmental issues whilst keeping the business safe.
Closing Thoughts
If I could condense this to just taking a single statement from each step, keep this in mind:
- Pre-prioritise your workload recovery order
- Identify your business risks
- Identify what the business needs before you worry about what it wants
- RPO doesn’t have to be universal to the workload, understand what components make it important and protect them.
- Perform test runs to give your policy meaning, the policy is useless unless enforcable.
- Expect and tolerate data protection issues as part of BAU, disaster tolerance and mitigation is the whole reason you’re writing this policy.