

If you missed the first part of this 3-part series, you can read it here. For the 2nd part, go here. This 3rd and final part in the Blog series will be a bit lengthier than the previous 2, but the extra content is worth the read.
In this 3rd post, I’ll be discussing the Backup Copy Job Long-Term (or GFS) Retention Policy. For the remainder of this post, I’ll just refer to this as ‘GFS Policy’. Over the years, I’ve generally felt Veeam’s User Guides have been fantastic. The best out there, in my opinion, are the VMware User Guides, with Veeam a close 2nd. Since about Veeam v9, when Veeam really started gaining steam implementing some of their best features to date – Storage Integration, expanding their Veeam Agent offering, etc, their User Guides have seemed to start lacking some needed information. I think part of the reason is they were jamming everything into one Guide and possibly cutting some corners. They really needed to start separating some features out of the main User Guide to break it up, since the User Guide was becoming way too lengthy. It appears recently they’ve started to do just that, but still. Anyway…I digress… another post for another time maybe ![]() The main point was to say I think Veeam needs some work on the Long-Term Retention section to better describe how it works.
The main point was to say I think Veeam needs some work on the Long-Term Retention section to better describe how it works.
With respect to Copy Jobs, when you enable the GFS Policy, Veeam states the GFS Policy ‘works in conjunction with the Short-Term Policy’, which is kinda true, kinda not in my opinion (I’ll get to this in a bit). Also, the Copy Job method will change from Forever Forward Incremental to Forward Incremental, as stated below.

The method switch is a change from previous Veeam versions. The only time the method changed pre-V11 was when you decided to enable Active Fulls (enabling the Read entire restore point from source instead of synthesizing it from increments option) with your Copy Job instead of using the default Synthetic Fulls. Another change in V11 Copy Jobs is doing away with the Quarterly GFS Retention option. With these 2 seemingly small changes, drastic results can ensue, at least with regards to storage space.
So let me now cover why the above statement in the User Guide is not too entirely clear, and was the foundation for my major point of confusion which then led to this Blog series. When you enable GFS for your Copy Jobs, your Copy Job chain starts as you would expect – a Full is created on first job run, then subsequent runs create Increments. The confusion for me was the Increments keep getting created, beyond your Short-Term Policy setting; and keep going until your first GFS Policy (Weekly, Monthly, or Yearly) is reached. My assumption was GFS worked *with* Short-Term, meaning the Short-Term Policy would still kick in and create Fulls and Increments which meet your Short-Term Policy, and keep the chain ‘moving forward’, using Synthetic or Active Fulls, until a configured GFS Policy is reached. But, this is not how the Copy Job GFS Policy works.
For example, let’s take the following minimal Copy Job Retention configuration:
- Short-Term Policy = 3 Restore Points
- GFS Policy = Weekly – 0; Monthly – 2; Yearly – 0
The first job run would be a Full; the 2nd run would be an Increment; 3rd run would be an Increment. My thinking (and thus confusion) was the 4th run would be an Increment, then either a Synthetic or Active Full would get created, starting a new Short-Term Policy chain. I then thought the next 3 subsequent Copy Job runs would create Incrementals, and the whole previous chain would be deleted. I thought this process would continue until you get to your first configured GFS Policy, which in this example is the 1st Monthly. But, this isn’t the restore point behavior for Copy Jobs when using GFS Policy. What happens in reality is this: the first run is a Full, then all subsequent runs are Increments…for however many days is needed until the first configured GFS Policy is reached, which in our example is a Monthly. On the GFS Policy day, a Synthetic or Active Full is created. All previous restore points will stay on disk. The next 2 Copy Job runs will produce Increments, which will then give us “3” in the active chain. After the 2nd Increment is created, all previous month-long restore points will then be removed from disk. This process will then repeat itself until the next configured GFS Policy is reached, and in our example here would be the 2nd Monthly. A 2nd Monthly Full would then get created, and the process continues as described. As you can see, this can lead to a lot of storage being required for your Copy Jobs. This is the reason why Veeam states in the User Guide:

If you’re using Monthly GFS Policy, the way to mitigate all these files and the need for a lot of extra storage space, is to configure just 1 Weekly. In doing so, the restore point behavior would be pretty much how I originally thought happened – the Weekly GFS would cycle through each week until the Monthly GFS is reached, and there wouldn’t be so many Increments, configured as shown below:
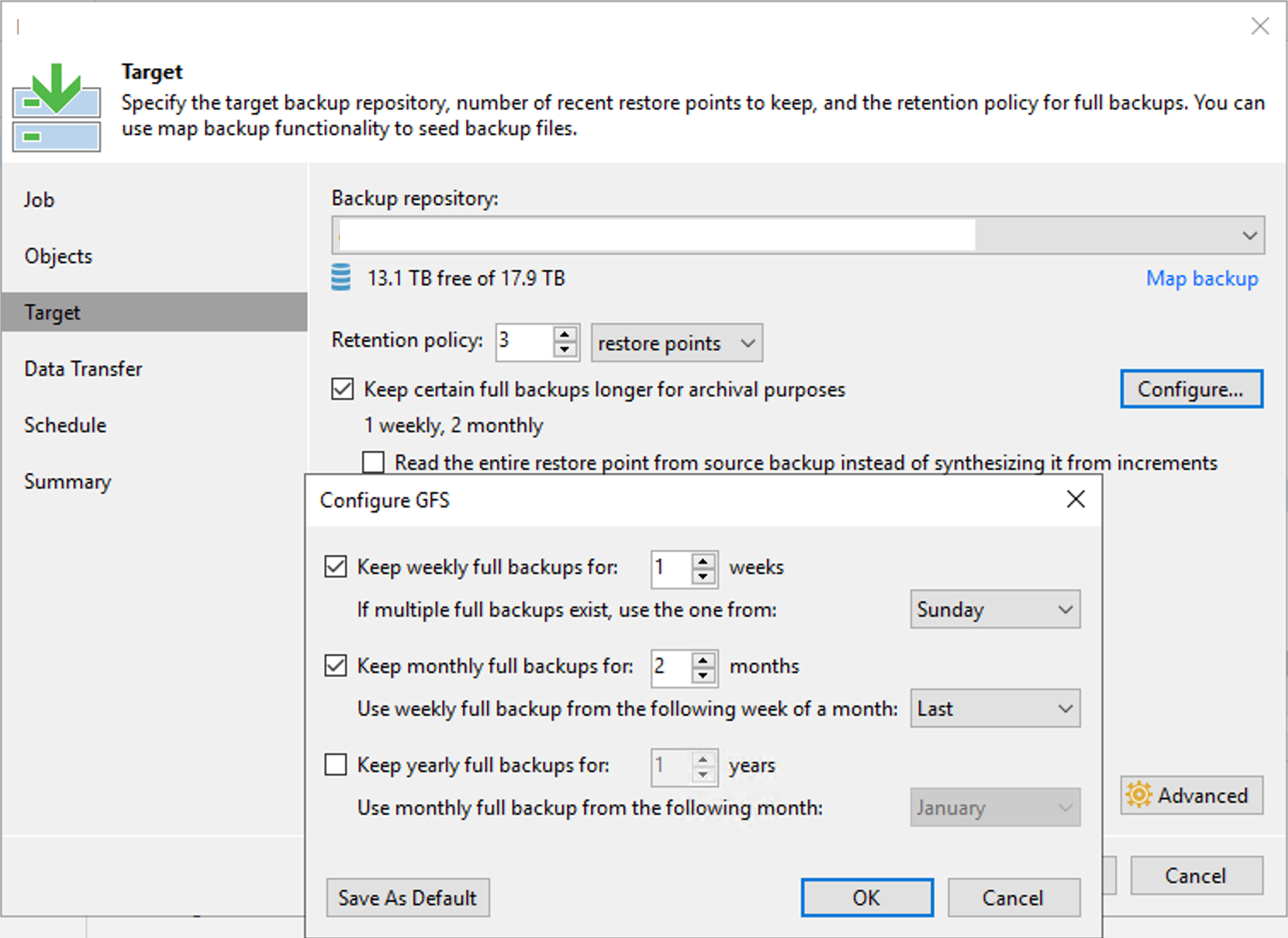
If you configured your Short-Term Policy to be in line with your GFS Policy (7 Short-Term restore points, then a configured Weekly; or, 30 Short-Term restore points, then a configured Monthly), you probably never noticed this behavior.
I personally think it would be better if Veeam would just say the following in the User Guide:
If you enable GFS Policy, you could have a long chain of Increments if you use Monthly or Yearly, and do not also include at least one Weekly. The reason is because Short-Term Retention is disregarded until the first configured GFS Policy is reached, at which point a GFS Full is created. When subsequent Increments after the GFS Full meets the Short-Term Policy, all previous Increments, and Fulls which do not belong to a GFS Policy, are then deleted from disk.
As I stated above, in previous versions of Veeam, the Forever Forward Incremental method was used for both Short (‘Simple’ in previous versions) and Long-Term Retention. Thus, the Short-Term chain would continue to ‘move forward’ until your first GFS Policy item was reached. This restore point behavior required less storage space in your Repository. I’m not entirely sure why Veeam changed the backup method in V11. I think it may have something to do with how immutable data is handled when sending it to an immutable target; but, not sure.
Also keep in mind one of the limitations I shared in Part I of this series: Short-Term Policy cannot delete or merge GFS Policy Fulls. Because GFS Fulls cannot be modified, the Short-Term Policy counts Retention only in the *active (current) chain*. As such, there will more than likely be additional files in the chain above what is configured in the Short-Term Policy; and there will always be at least 2 Full files on disk, a ‘R-Flag’ Full and a ‘GFS-Flag’ (W, M, Y) Full, once you reach your first configured GFS Policy. Do you now understand why Copy Jobs confused me? ![]()
This is a good segue into briefly covering the last part of this post, GFS Flags – a letter designation Veeam assigns to Copy Job Full files. Checking Flags allows you to keep track and verify your Copy Job restore point behavior. How can you check which Full has which Flag, beit Regular or GFS? Within the Veeam Console, from the Home node, under the Backups section, select Disk (Copy). In the Working Area on the right, rt-click on the desired Copy Job and choose Properties. Select a VM in the ‘Objects’ window, then in the bottom ‘Files’ window you can view the Flags associated with the Full files, as shown below:
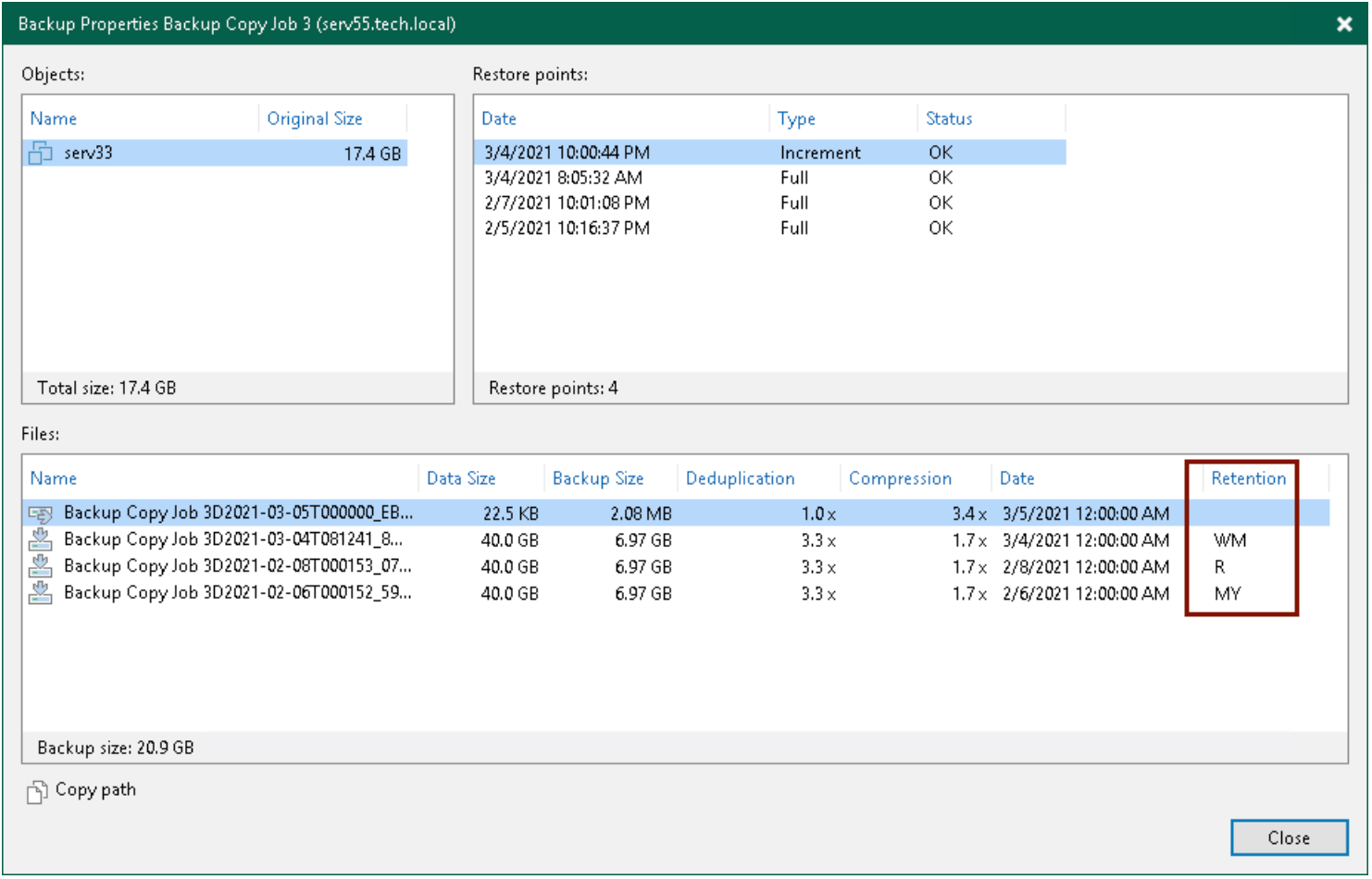
And there you have it – deep-diving into Veeam’s Copy Jobs. Hopefully this Blog series “demystified” the mystery behind how Copy Jobs function for you. I also want to give a shout out to Rick Vanover, Veeam Senior Director of Product Strategy, for giving a technical review of this post.
If you have any questions, see any errors, or need further explanations on anything in the Blog series, please leave a comment below.
Cheers!





