


Data Quality C.A.R.E. is a framework that emphasizes essential aspects of data quality, particularly in the context of Machine learning (ML) and Deep Learning (DL).
Before we describe the framework, it is important to remember essential concepts.
Machine Learning is a subset of Artificial Intelligence (AI) that enables systems to learn from data and improve their performance over time without being explicitly programmed.
It is generally effective with smaller datasets and can perform well with a few hundred or thousand samples. It is commonly used for structured data tasks like fraud detection, customer segmentation, and predictive analytics.
Deep Learning is a specialized subset of Machine Learning that uses neural networks with many layers (deep neural networks) to model complex patterns in data.
It requires large volumes of data to train effectively, often needing millions of samples to avoid overfitting and to capture complex patterns. Deep Learning excels in unstructured data tasks such as image recognition, natural language processing, and speech recognition, where it can outperform traditional ML methods.
L.L.M.s (Large Language Models) are specialized deep-learning models tailored to language tasks. Classic examples are GPT-4, Gemini, and Claude.
Adopting a Data Quality Framework is crucial for Machine Learning (ML) and Deep Learning (DL) initiative success in organizations:
- The accuracy and reliability of ML and DL models heavily depend on the data quality used for training. A robust data quality framework ensures the data is complete, accurate, and relevant.
- High-quality data helps models learn the correct patterns, avoiding producing biased or incorrect predictions undermining their utility.
- A structured approach to data quality helps identify and eliminate noise and inconsistencies in the data.
- Data preparation and cleaning can be time-consuming and costly in the ML/DL pipeline.
- Reliable data leads to accurate analyses, which are essential for informed decision-making.
- Maintaining high data quality is vital for compliance, data governance, and privacy regulations.
- A solid data quality framework allows for scalable data quality management.
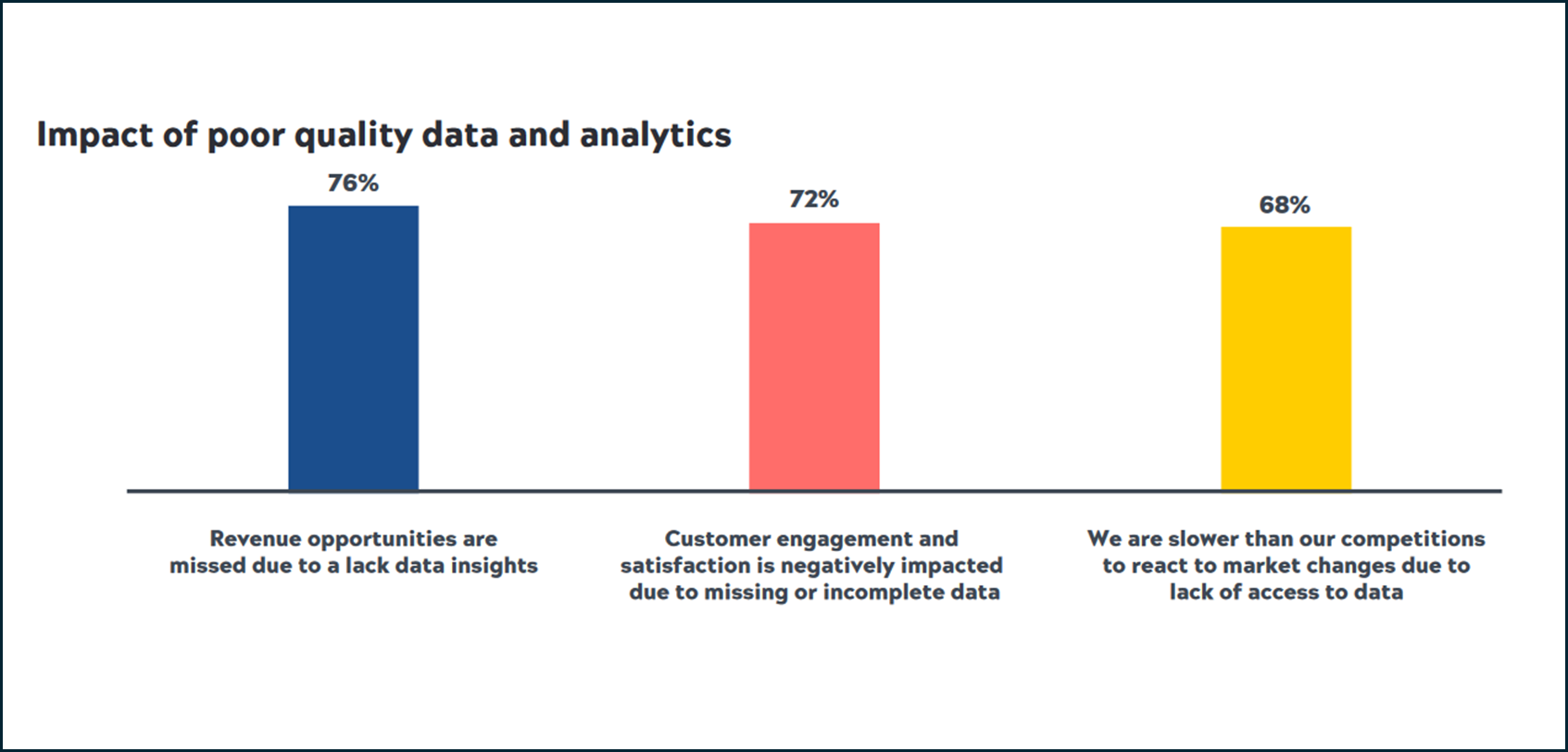
Source:
The Data Quality Framework C.A.R.E. is a structured approach designed to assess and enhance data quality within organizations.
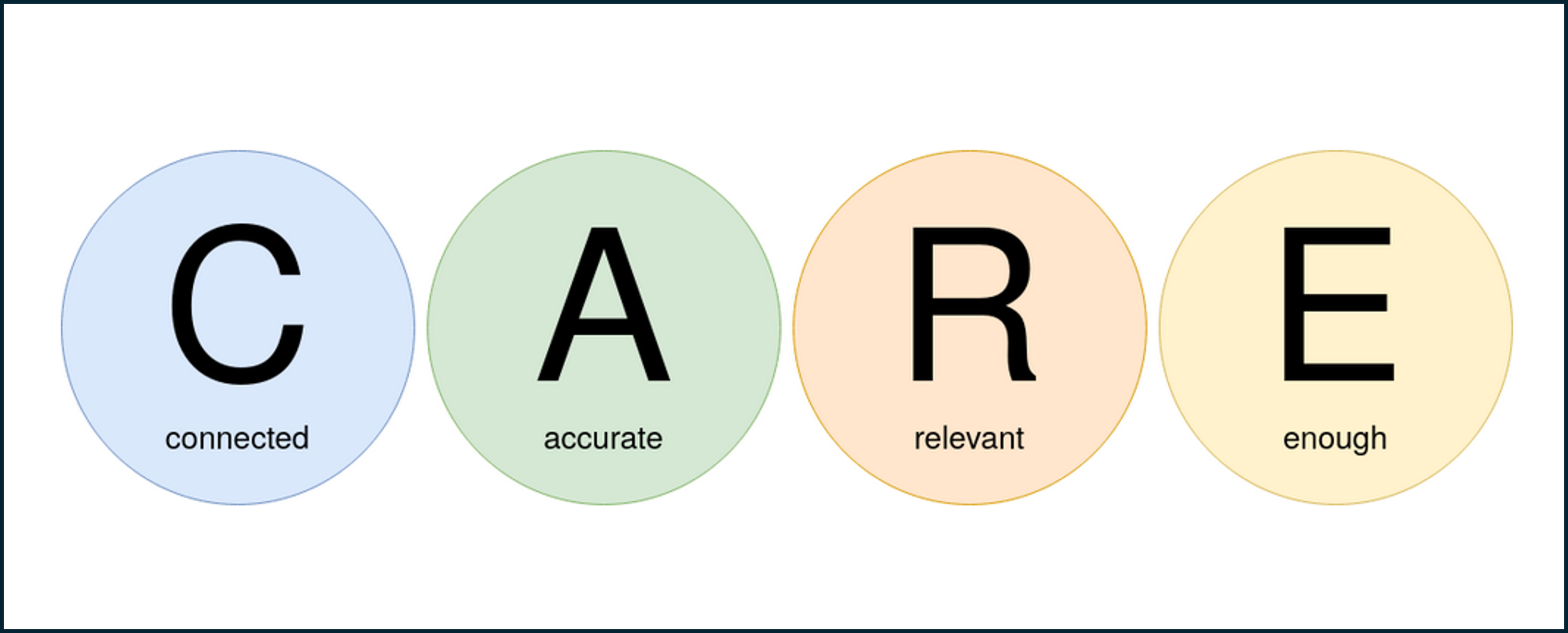
The acronym C.A.R.E. represents four essential dimensions of data quality:
Connected
The data is connected if it has no gaps; all required data is present.
Disconnected data can lead to biased insights and poor outcomes. It is also harder to handle because most algorithms cannot handle them. If records containing missing data are discarded or considered, it leads to assumptions and biases.
Accurate
Accuracy measures how closely data values reflect the real-world entities or conditions. It assesses the correctness of the data; there are little or no measurement errors.
Inaccurate data may silently break a model since values wildly outside the expected range may skew the model, impacting performance or producing absurd predictions. It can lead to losing trust in the model and potentially costly errors. Ensuring accuracy builds confidence in the data and its derived conclusions.
Relevant
The data is relevant if it is related to the task or the phenomenon context. This dimension focuses on ensuring that the data meets the users' needs.
Using relevant data helps minimize distractions from unnecessary information, allowing organizations to focus on what truly matters for their analyses and decisions. Relevant data enhances the effectiveness of insights drawn from analyses.
Enough
It is necessary to define the amount of data depending on the model's complexity and the associated costs to store and process it.
Enough data management practices lead to cost savings and streamlined operations.
Organizations can enhance productivity, reduce processing times, and focus more on analysis than data handling by optimizing data processes.
It is also possible to reduce costs using data augmentation, which incorporates more data in a dataset to train a model without collecting more data.
In conclusion, adopting a data quality framework like C.A.R.E is essential for successfully deploying Machine Learning and Deep Learning initiatives with good results and saving costs. It is critical to avoid data distrust - a lack of confidence or skepticism regarding data quality, integrity, or reliability.
You can also access this and other articles/post on my blog: https://cloudnroll.com/
References:
https://www.gartner.com/smarterwithgartner/how-to-improve-your-data-quality
https://training.linuxfoundation.org/training/pytorch-and-deep-learning-for-decision-makers-lfs116/
https://profisee.com/data-quality-what-why-how-who/
https://bi-survey.com/data-quality-master-data-management
