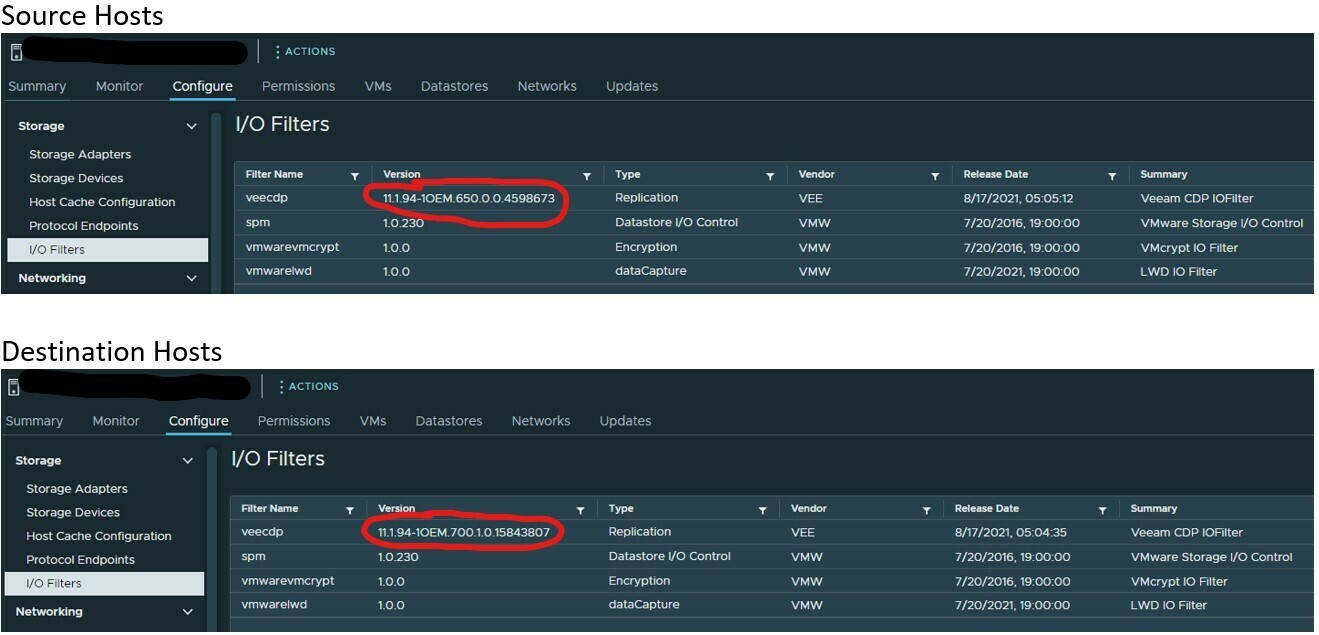
Tried looking for this, but does a VM have to have a minimum version for CDP Replication? Turning up CDP for the first time for two VM’s and getting the below error. Or am I going about this wrong?
6/27/2022 4:58:31 PM :: VM configuration for the initial sync completed with errors Error: The virtual machine version is not compatible with the version of the host 'esxi02'. (The version of the IO Filter(s) 'VEE_bootbank_veecdp_11.1.94-1OEM.700.1.0.15843807' configured on the VM's disk are not compatible with the one installed on the destination host.): first occurrence at 6/27/2022 3:52:02 PM, last occurrence at 6/27/2022 4:59:02 PM, 91 retries
6/27/2022 5:01:17 PM :: Failed to configure source disks Error: The virtual machine version is not compatible with the version of the host 'esxi01'. (The version of the IO Filter(s) 'VEE_bootbank_veecdp_11.1.94-1OEM.700.1.0.15843807' configured on the VM's disk are not compatible with the one installed on the destination host.)
Source Host: ESXi 7.0.3 19482537
Destination Host: ESXi 7.0.3 19898904
VM Hardware version’s: 8 & 11
Best answer by dloseke
View original