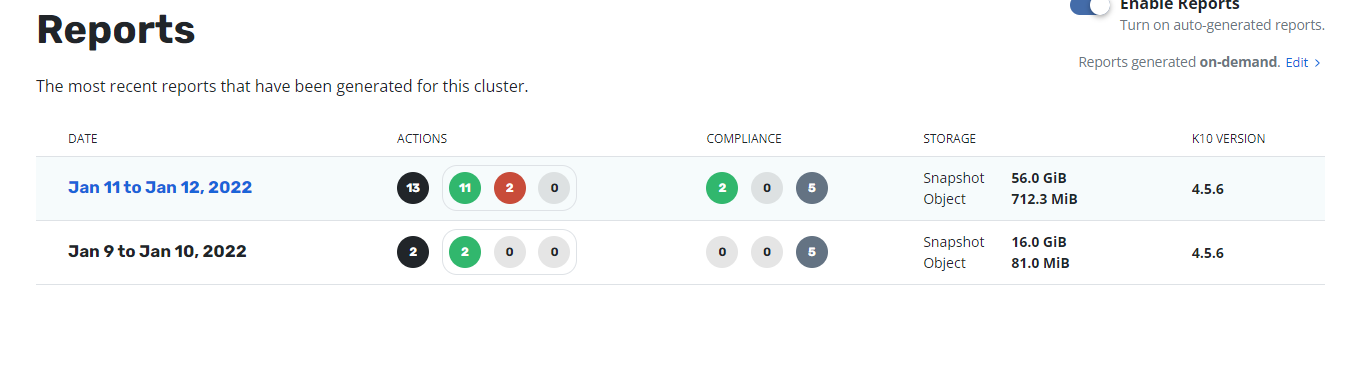
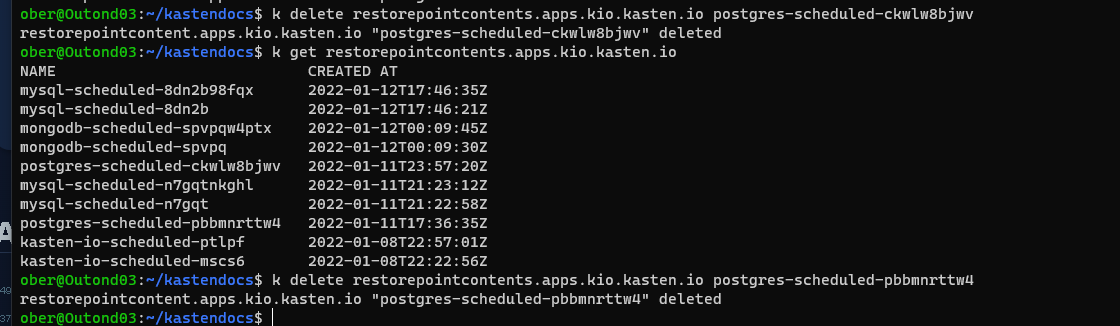
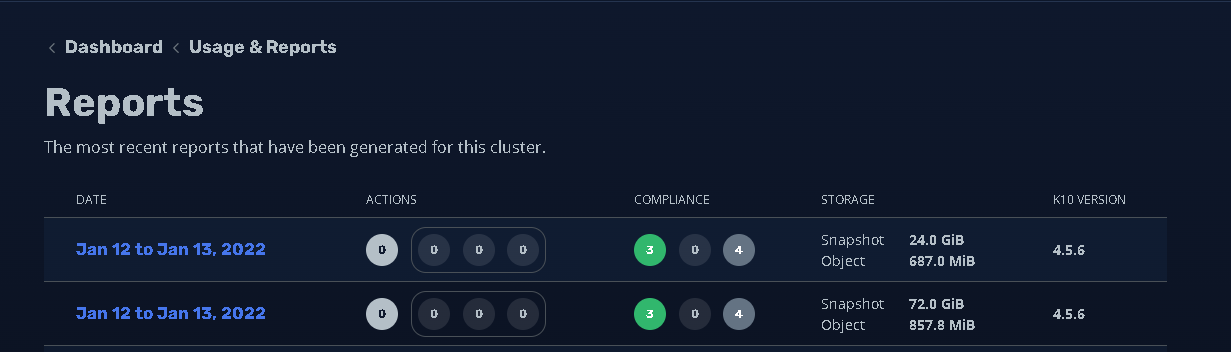
Hi! I’m using a NFS share for K10 DR. The retention policy in the DR policy was changed to only keep 1 hourly version. Therfore only one version should be kept. It looks liket the old version get retired. But the space on the nfs volume isn’t freed up. Also the usage report shows that the storage is in use by kasten-io. What can I do to free up the space? Is there any manual disk space reaclaim job which needs to be run?
Best answer by Hagag
View original